








Система Smart Engines масштабируется под любые объемы бизнеса. ИИ обрабатывает до 600 тысяч страниц в сутки на одном сервере и до 16 млн страниц на кластере без использования графических процессоров (GPU) и усложнения ИТ-ландшафта. Решение обеспечивает высокое качество и непревзойденную скорость распознавания документов даже при пиковых нагрузках.
ИИ-система Smart Engines обеспечивает шрифтонезависимое (омнифонтовое) распознавание документов на более чем 100 языках — независимо от гарнитуры, начертания и качества печати. Решение одинаково точно работает с латиницей и кириллицей, а также с наиболее сложными системами письма — арабской вязью, иероглифами китайского и японского языков, корейским письмом и другими алфавитами.
В основе программного решения лежит собственная технология оптического распознавания текста (OCR), разработанная Smart Engines. Все используемые нейросетевые алгоритмы и программный код полностью созданы специалистами компании. Такой подход позволяет контролировать все этапы обработки данных без необходимости использования сторонних библиотек или сервисов.
ИИ Smart Engines распознает сканы и фотографии в реальных условиях — включая изображения низкого качества. Алгоритмы устойчивы к шуму, размытию, перекосам и плохому освещению, что обеспечивает точное извлечение данных даже там, где традиционные OCR-решения теряют точность.
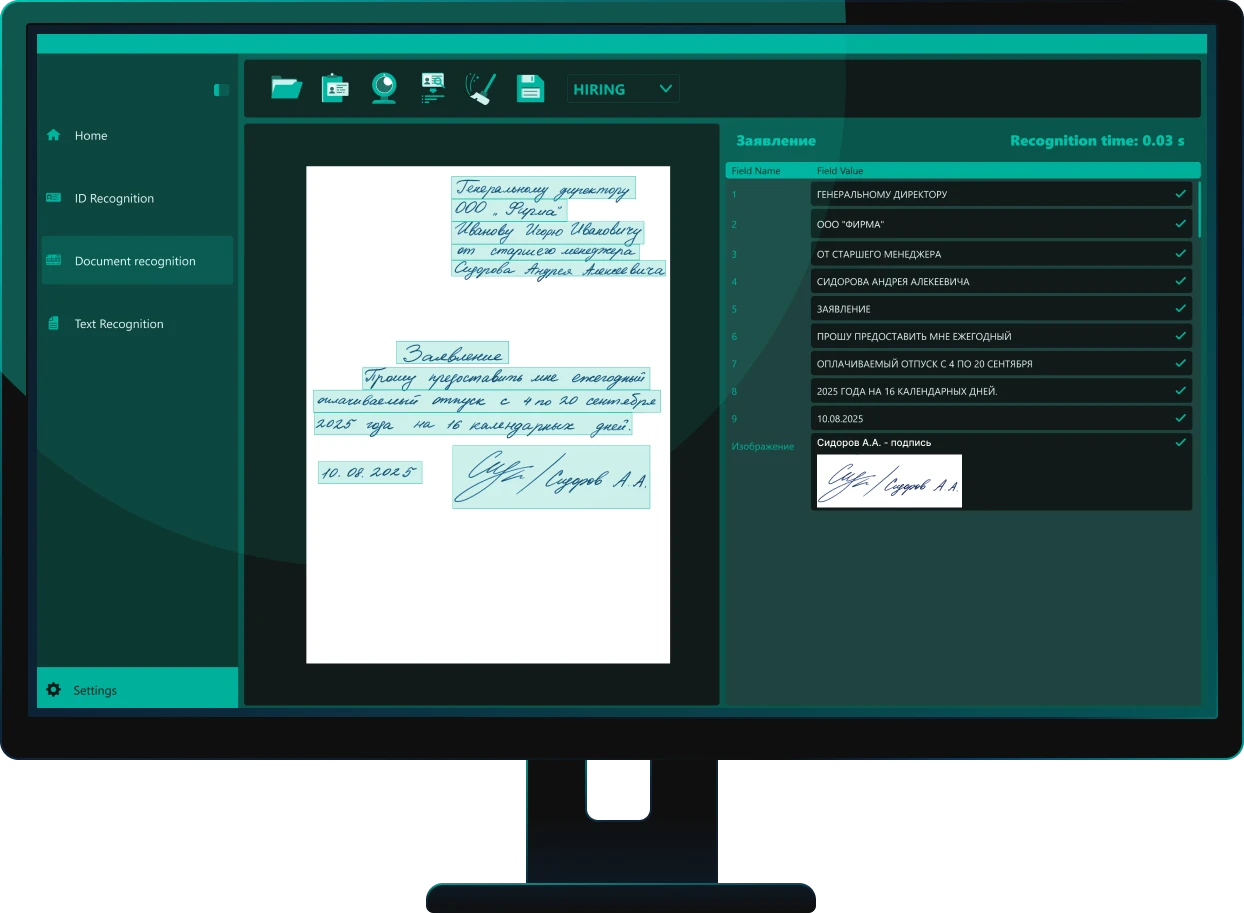
Система распознает печатные, рукопечатные и рукописные реквизиты с точностью до 99,9%. Алгоритмы ИИ позволяют считывать практически любой почерк — от аккуратного до трудноразборчивого — а также текст, написанный ручкой, карандашом или пером. Поддерживается распознавание пометок и комментариев на документах.
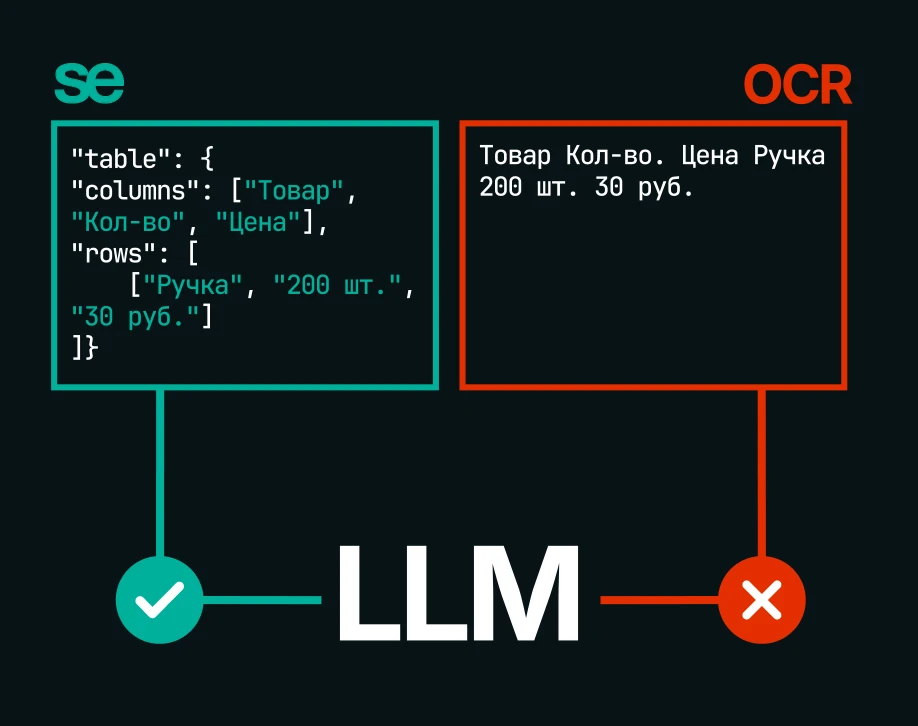
Система Smart Engines извлекает данные из документов в исходном виде «как есть» (as is) — без какого-либо вмешательства в данные. В отличие от генеративных моделей, склонных к искажению данных и «галлюцинированию», такой подход обеспечивает точность и надежность, критичные для бизнес-процессов.
Минимальный футпринт — всего 2,7 МБ для веб-страниц и PWA — достигается за счет использования сверхкомпактных нейросетевых архитектур, оптимизированных по числу параметров и потреблению памяти. Это позволяет запускать модели непосредственно на устройстве, обеспечивая быструю работу на мобильных устройствах и даже в браузере без потери точности.
Система Smart Engines обеспечивает распознавание текста, оптимизированное для работы с большими языковыми моделями (LLM). Она формирует структурированный и высокоточный вывод данных без шума и искажений. Это упрощает интеграцию с языковыми моделями и повышает качество их работы.
Решение работает как на серверах компании, так и на десктопах, смартфонах и планшетах пользователей — интеграция возможна в мобильные приложения или браузер. Все вычисления выполняются локально — без передачи данных во внешние сервисы. Система подходит для выездных и удаленных сценариев проверки и не требует стабильного интернет-соединения.
Как работает распознавание текста
Система оптического распознавания текста на базе собственной AI OCR, предназначенная для быстрого и точного ввода документов на 100+ языках. ПО работает со сканами и фотографиями низкого качества, распознает печатный, рукописный и смешанный текст без лингвистических галлюцинаций, возвращая именно то, что указано на бумаге. Система обрабатывает документы в мобильных, веб-, десктопных и серверных приложениях, работает полностью автономно в контуре заказчика и не требует GPU.Обеспечивает минимальный футпринт для PWA и веба. Распознает входящую корреспонденцию, клиентские документы, финансовые документы и другие со скоростью более 100 тысяч страниц в час на сервере для ввода документов в LLM, СЭД, ERP, CRM и архивы.
Возможности распознавания
- OCR документа в мобильном, веб, десктоп и серверном приложении
- Распознавание сканов и фотографий низкого качества
- Поиск, выравнивание и нормализация документа на фотографии
- Распознавание документа А4 на смартфоне за 2-3 секунды
- GreenOCR® — экологичный искусственный интеллект для распознавания текста
- Уникальные 4.6 битные нейросетевые модели для скоростного распознавания на CPU
- Распознавание силами CPU, не требует серверов с GPU и NPU
- Высокоточное распознавание текста на фото и скане
- Распознавание рукописных текстов, надписей и пометок вне зависимости от почерка
- Автоматизация ввода текста документов для СЭД и электронных архивов
- Новаторские малобитные и компактные нейросетевые модели
- Распознавание печатной и рукописной кириллической письменности
- Высокоточный OCR для всех языков, базирующихся на латинице
- Распознавание арабского, фарси, урду, бенгальского, тайского, сингальского и тамильского
- Распознавание японского, корейского и китайского языков
- Распознавание иврита, греческого, грузинского и армянского
- Распознавание многостраничных документов
- Поиск и распознавание таблиц
- Потоковое распознавание в контуре (on-premise) со скоростью более 100 тысяч страниц в час на сервере без GPU
- Надежное распознавание рукописи и печатного текста без лингвистических галлюцинаций
- AI модели обучены исключительно на синтетических данных
- Автоматическое определение типа документа
Возможности
интеграции
TextEngine engine = TextEngine.Create(<PATH_TO_CONFIGURATION_FILE>, true);
TextSessionSettings session_settings = engine.CreateSessionSettings();
settings.SetOption("mode", "page");
settings.AddEnabledLanguages("rus:eng:punct:digits");
TextSession session = engine.SpawnSession(settings, <PERSONALIZED_SIGNATURE>);
Image image = Image.FromFile(<PATH_TO_IMAGE>);
session.ProcessImage(image);
TextResult result = session.GetCurrentResult();
TextScene scene = result.GetCurrentScene();
TextIterator iterator = scene.CreateIterator("default");
while(!iterator.Finished()) {
String chunk = iterator.GetTextChunk().GetOcrString().GetFirstString().GetCStr();
chunk_iterator.Advance();
}
std::unique_ptr<se::text::TextEngine> engine(se::text::TextEngine::Create(<PATH_TO_CONFIGURATION_FILE>, true));
std::unique_ptr<se::text::TextSessionSettings> settings(engine->CreateSessionSettings());
settings->SetOption("mode", "page");
settings->AddEnabledLanguages("rus:eng:punct:digits");
std::unique_ptr<se::text::TextSession> session(engine->SpawnSession(*settings, <PERSONALIZED_SIGNATURE>));
std::unique_ptr<se::common::Image> image(se::common::Image::FromFile(<PATH_TO_IMAGE>));
session->ProcessImage(*image);
const se::text::TextResult& result = session->GetCurrentResult();
const auto& scene = result.GetCurrentScene();
auto iterator = scene.CreateIterator("default");
for (; !iterator->Finished(); iterator->Advance()) {
std::string chunk = iterator->GetTextChunk().GetOcrString().GetFirstString().GetCStr();
}
TextEngine engine = TextEngine.Create(<PATH_TO_CONFIGURATION_FILE>);
TextSessionSettings settings = engine.CreateSessionSettings();
settings.SetOption("mode", "page");
settings.AddEnabledLanguages("rus:eng:punct:digits");
TextSession session = engine.SpawnSession(settings, <PERSONALIZED_SIGNATURE>);
Image image = Image.FromFile(<PATH_TO_IMAGE>);
session.ProcessImage(image);
TextResult result = session.GetCurrentResult();
TextScene scene = result.GetCurrentScene();
for (TextIterator iterator = scene.CreateIterator("default"); !iterator.Finished(); iterator.Advance()) {
String chunk = iterator.GetTextChunk().GetOcrString().GetFirstString().GetCStr();
}
engine = pytextengine.TextEngine.Create(<PATH_TO_CONFIGURATION_FILE>)
settings = engine.CreateSessionSettings()
settings.SetOption("mode", "page")
settings.AddEnabledLanguages("rus:eng:punct:digits")
session = engine.SpawnSession(settings, <PERSONALIZED_SIGNATURE>)
image = pyidengine.Image.FromFile(<PATH_TO_IMAGE>)
session.ProcessImage(image)
result = session.GetCurrentResult()
scene = result.GetCurrentScene()
iterator = scene.CreateIterator("default")
while not iterator.Finished():
chunk = iterator.GetTextChunk().GetOcrString().GetFirstString().GetCStr()
chunk_iterator.Advance()
Уверенность распознавания, координаты объектов, вырезание полей и документов
Возврат зоны принятия решения для проверок подлинности

Попробуйте качество наших технологий
- Скачайте мобильное демо-приложение, в котором все возможности собраны воедино
- Можно на время отключить интернет, чтобы убедиться, что изображения и ваши данные не передаются
- Извлекайте данные паспортов, удостоверений личности и других документов. Пробуйте распознавать оригиналы и копии при различных условиях съемки.


