







ИИ Smart Engines сокращает время обработки бухгалтерских документов до 50 раз и повышает точность в 1,5 раза по сравнению с ручным вводом. Решение помогает автоматизировать рутинные операции, снизить нагрузку на бухгалтерию и минимизировать ошибки при обработке документов. Бесшовная интеграция с 1С и ERP-системами позволяет быстро направить данные в целевые бизнес-процессы без доработок и усложнения текущих операций.
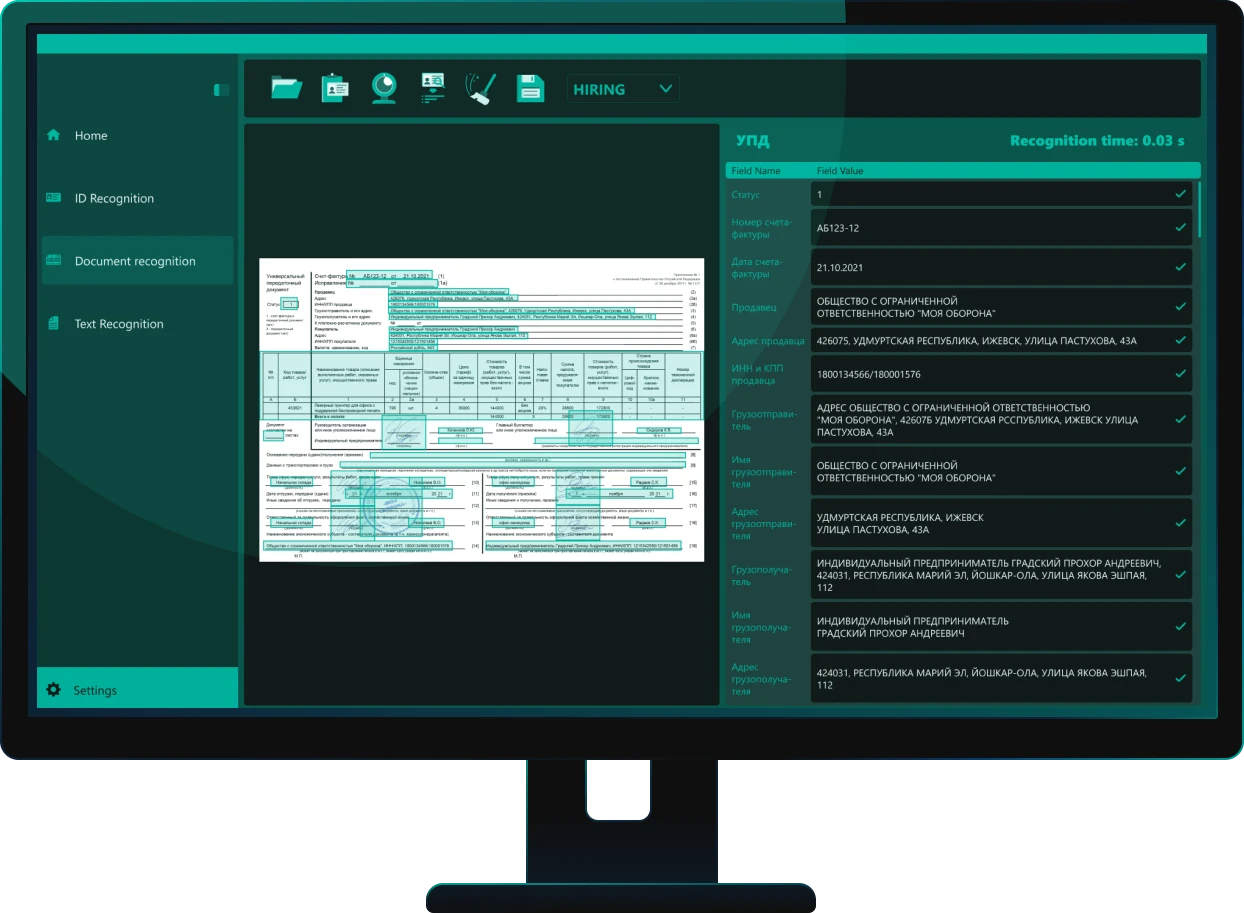
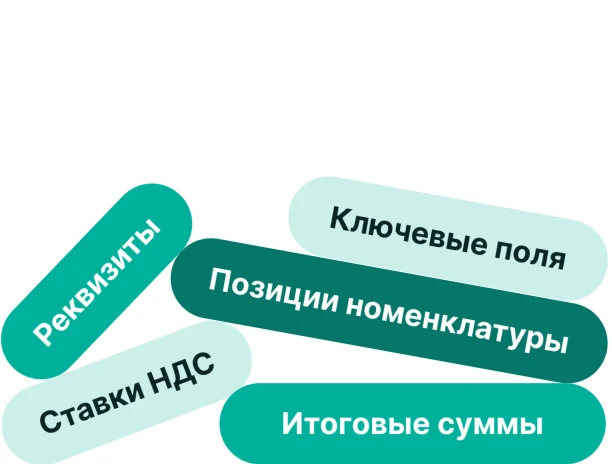
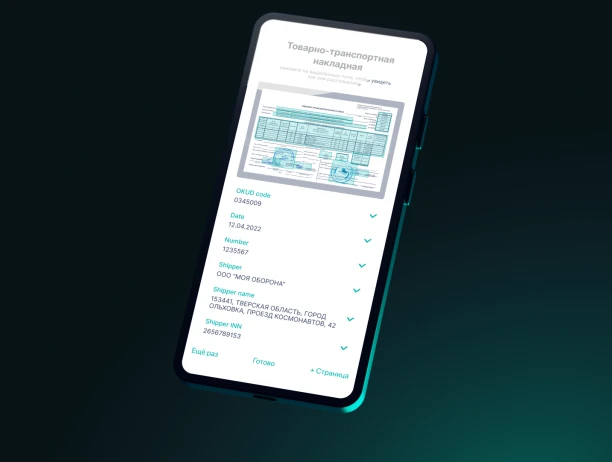
Система извлекает 100% ключевой информации из первичных бухгалтерских документов: данные контрагентов, номенклатуру, даты, суммы и ставки НДС. Решение понимает структуру документа и распознает сложные табличные формы и графические элементы, включая подписи и печати. Пользователь за секунды получает готовые структурированные данные для учета НДС, налогов по УСН, бухгалтерского учета, подготовки отчетности и других ключевых задач.
Технология Smart Engines позволяет обрабатывать документы в любом месте без привязки к рабочему месту или сканеру. Технология поддерживает работу в серверных, десктопных, мобильных и веб-приложениях, обрабатывая данные локально на конечном устройстве или на внутреннем сервере заказчика. Подходит для выездных сотрудников, сервисов бухгалтерии, складов и распределенных команд.
ИИ Smart Engines с высокой точностью распознает и извлекает любые рукописные реквизиты и пометки в документах. Решение подходит для обработки личных и корпоративных документов с рукописным заполнением, заявлений, анкет и документов с пометками и подписями. Это обеспечивает распознавание всей содержащейся в документе информации и помогает исключить потерю данных.
Алгоритмы ИИ автоматически определяют тип документа из более чем 80 преднастроенных шаблонов для быстрого распознавания, классификации и направления данных в целевые бизнес-процессы. Решение позволяет создать единую точку ввода и сортировки информации из любых бухгалтерских документов вне зависимости от их типа. Это дает возможность организовать полностью управляемый и прозрачный документооборот без ручной обработки.
Система Smart Engines масштабируется под любые объемы бизнеса. Обрабатывайте до 600 тысяч страниц в сутки на одном сервере и до 16 млн страниц на кластере без использования графических процессоров (GPU) и усложнения ИТ-ландшафта. Решение обеспечивает высокое качество и непревзойденную скорость распознавания бухгалтерских документов даже в пиковых нагрузках.
Решение сохраняет структуру и логику многостраничных документов, обрабатывая их как единое целое. Система сохраняет логические связи между страницами и извлекает данные без потери последовательности. Это позволяет использовать решение для надежной обработки актов, накладных, УПД, договоров и других многостраничных бухгалтерских документов.
Решение обеспечивает гибкое распознавания бухгалтерских документов вне зависимости от оформления. Система анализирует структуру и содержание без жесткой привязки к шаблону, что позволяет с высокой точностью распознавать документы с разным расположением элементов и от разных контрагентов. Это обеспечивает единый высокий стандарт скорости и качества обработки любых документов.
Решение обрабатывает документы полностью локально внутри инфраструктуры заказчика без передачи данных во внешние сервисы. Это обеспечивает защиту персональных данных, коммерческой тайны и другой конфиденциальной информации от разглашения, неавторизованного доступа и утечек. Подходит для любых компаний с требованиями к конфиденциальности.
Как работает распознавание бухгалтерских документов
Обеспечивает быстрое и точное распознавание первичных документов для автоматического ввода в 1С и ERP — быстрее и точнее бухгалтера. Решение автоматически классифицирует первичные бухгалтерские документы во входящем потоке, распознает сканы и фотографии, включая низкокачественные изображения. Система автоматически находит и распознает реквизиты, таблицы, суммы, ставки НДС, печатные и рукописные данные. Поддерживаются многостраничные документы, различные варианты оформления (без жестких шаблонов). Осуществляется проверка подписей и печатей, наличие и содержимое штампов ЭЦП. Автоматически проверяется цветность и выявляются признаки цифровой подделки документа. Система позволяет обрабатывать входящие поток (бумага, электронная почта, ЭДО, архив и т. п.) документов на сервере (без GPU) с производительностью 600 тысяч страниц в сутки, обеспечивает распознавание на мобильном телефоне и веб-странице без интернета.
Возможности распознавания
- Распознавание сканов и фотографий низкого качества
- Автоматическая классификация и сортировка при потоковой обработке документов
- Распознавание многостраничных документов первичной бухгалтерской отчетности
- Автоматический поиск и распознавание печатных и рукописных реквизитов, таблиц, чекбоксов, штрихкодов
- Проверка наличия и цвета подписей и печатей в процессе обработки финансовых документов
- Проверка цифрового вмешательства в изображение документа
- Проверка целостности данных документа
- Контроль цветности документа (выявление фотокопий)
- Распознавание текстов штампов и печатей
- Распознавание штампов ЭЦП
- Распознавание силами CPU, не требует серверов с GPU
- Автоматическое определение типа документа
- Собственная проприетарная технология распознавания текста GreenOCR
- Специальные 4.6 битные нейросетевые модели для мгновенного поиска и распознавания
- Распознавание рукописи вне зависимости от почерка
- Распознавание полностью рукописных документов
- Надежное распознавание рукописи и печатного текста без лингвистических галлюцинаций
Какие документы
распознаются
Возможности
интеграции
DocEngine engine = DocEngine.Create(<PATH_TO_CONFIGURATION_FILE>, true);
DocSessionSettings settings = engine.CreateSessionSettings();
settings.SetCurrentMode("primary_accounting");
settings.AddEnabledDocumentTypes("*");
DocSession session = engine.SpawnSession(settings, <PERSONALIZED_SIGNATURE>);
DocProcessingSettings proc_settings = session.CreateProcessingSettings();
Image image = Image.FromFile(<PATH_TO_IMAGE>);
session.ProcessImage(image, proc_settings);
DocResult result = session.GetCurrentResult();
Document document = result.DocumentsBegin().GetDocument();
for (DocTextFieldsIterator iterator = doc.TextFieldsBegin(); !iterator.Equals(doc.TextFieldsEnd()); iterator.Advance()) {
String name = iterator.GetField().GetBaseFieldInfo().GetName();
String value = iterator.GetField().GetOcrString().GetFirstString().GetCStr();
}
std::unique_ptr<se::doc::DocEngine> engine(se::doc::DocEngine::Create(<PATH_TO_CONFIGURATION_FILE>, true));
std::unique_ptr<se::doc::DocSessionSettings> settings(engine->CreateSessionSettings());
settings->SetCurrentMode("primary_accounting");
settings->AddEnabledDocumentTypes("*");
std::unique_ptr<se::doc::DocSession> session(engine->SpawnSession(*settings, <PERSONALIZED_SIGNATURE>));
std::unique_ptr<se::doc::DocProcessingSettings> proc_settings(session->CreateProcessingSettings());
std::unique_ptr<se::common::Image> image(se::common::Image::FromFile(<PATH_TO_IMAGE>));
session->ProcessImage(*image, proc_settings.get());
const se::doc::DocResult& result = session->GetCurrentResult();
const se::doc::Document& doc = result.DocumentsBegin().GetDocument();
for (auto iterator = doc.TextFieldsBegin(); iterator != doc.TextFieldsEnd(); ++iterator) {
std::string name = iterator.GetFieldPtr()->GetBaseFieldInfo().GetName();
std::string value = iterator.GetFieldPtr()->GetOcrString().GetFirstString().GetCStr();
}
DocEngine engine = DocEngine.Create(<PATH_TO_CONFIGURATION_FILE>, true);
DocSessionSettings settings = engine.CreateSessionSettings();
settings.SetCurrentMode("primary_accounting");
settings.AddEnabledDocumentTypes("*");
DocSession session = engine.SpawnSession(session_settings, <PERSONALIZED_SIGNATURE>);
DocProcessingSettings proc_settings = session.CreateProcessingSettings();
Image image = Image.FromFile(<PATH_TO_IMAGE>);
session.ProcessImage(image, proc_settings);
DocResult result = session.GetCurrentResult();
doc_it = recog_result.DocumentsBegin()
Document doc = recog_result.DocumentsBegin().GetDocument();
for (DocTextFieldsIterator iterator = doc.TextFieldsBegin(); !iterator.Equals(doc.TextFieldsEnd()); iterator.Advance()) {
String name = iterator.GetField().GetBaseFieldInfo().GetName();
String value = iterator.GetField().GetOcrString().GetFirstString().GetCStr());
}
engine = pydocengine.DocEngine.Create(<PATH_TO_CONFIGURATION_FILE>)
settings = engine.CreateSessionSettings()
settings.SetCurrentMode("primary_accounting")
settings.AddEnabledDocumentTypes("*")
session = engine.SpawnSession(settings, <PERSONALIZED_SIGNATURE>)
proc_settings = session.CreateProcessingSettings()
image = pydocengine.Image.FromFile(<PATH_TO_IMAGE>)
session.ProcessImage(image, proc_settings)
result = session.GetCurrentResult()
doc_it = recog_result.DocumentsBegin()
doc = recog_result.DocumentsBegin().GetDocument()
iterator = doc.TextFieldsBegin()
while(iterator != doc.TextFieldsEnd()):
name = iterator.GetField().GetBaseFieldInfo().GetName()
value = iterator.GetField().GetOcrString().GetFirstString().GetCStr()
iterator.Advance()
Уверенность распознавания, координаты объектов, вырезание полей и документов
Возврат зоны принятия решения для проверок подлинности

Попробуйте качество наших технологий
- Скачайте мобильное демо-приложение, в котором все возможности собраны воедино
- Можно на время отключить интернет, чтобы убедиться, что изображения и ваши данные не передаются
- Извлекайте данные паспортов, удостоверений личности и других документов. Пробуйте распознавать оригиналы и копии при различных условиях съемки.


