22.06.2020 г.
Эволюция баркода
Баркод, безусловно, относится к одному из тех изобретений человечества, которые изменили течение нашей жизни. Благодаря появлению штрихового кодирования и его последующей эволюции, многие обыденные действия не только значительно упростились и ускорились, но иногда и приобрели неожиданные формы. В процессе нашей деятельности по разработке и улучшению алгоритмов интеллектуального распознавания документов (IDR) и движка распознавания баркодов Smart BarcodeReader мы постоянно систематизируем знания в предметной области. Понимание того, как развивается технология, позволяет нам совершенствовать наши разработки, делать их более быстрыми, точными и эффективными. Сегодня мы расскажем о том, как эволюционировал (и продолжает эволюционировать) баркод от линейного черно-белого рисунка к многомерной конструкции.
Как и большинство изобретений, первое поколение баркодов — линейный одномерный штрихкод — появился, когда возникла острая необходимость автоматизировать достаточно простую, но рутинную и кропотливую работу по сортировке и учету товаров в процессе логистики и продажи: что поступает на склад, что уходит со склада, что отгружается клиентам и в каком ассортименте. Когда все эти процессы неизбежно сопровождаются ручным заполнением необходимых документов, поиском нужной полки на складе, формированием отчетности по логистике, то требуются значительные затраты времени сотрудника. Кроме того, ошибки при ручном заполнении документов неизбежны. Рост товарооборота требовал кардинального решения, которое бы позволило быстро и без ошибок решать задачи контроля и учета.
Идея кодирования товаров появилась одновременно с идеей организации работы “идеального супермаркета”, разработанной студентом Гарвардской школы бизнеса Уоллесом Флинтом в начале 1930-х годов. Предложенное техническое решение предполагало, что покупатель самостоятельно формирует перечень покупок на складе, делая проколы в специальной перфокарте покупателя. На кассе эта перфокарта по задумке должна была считываться специальным устройством, товары подавались при помощи специального транспортера, а процесс обслуживания был быстрым и для покупателя, и для продавца. Главная проблема заключалась в том, что на тот период технологии и оборудование для обслуживания подобных процессов практически отсутствовали: ЭВМ, которая требовалась бы для организации считывания и обработки информации подобного класса была бы слишком громоздка и дорога.
Следующий подход к кодированию товарного ассортимента был предпринят в 1948 году, когда аспирантами-энтузиастами из Дрексельского технологического института (США) началась проработка технологии сбора аналитической информации о покупках непосредственно на кассах в супермаркетах на основании маркировки товаров. Тогда группа исследователей создала “гибрид” технологии оптической звуковой дорожки (optical soundtrack) и азбуки Морзе. В классической технологии оптической звуковой дорожки по краю кинопленки наносится покрытие с неравномерной плотностью. Эта неравномерность приводит к тому, что интенсивность луча проектора, проходящего через него, также изменяется. Эти колебания яркости и преобразуются в звук.
Исследователи трансформировали точки и тире азбуки Морзе в неравномерные полосы как бы “вытянув” их вниз. В результате получилась последовательность широких вертикальных линий (тире) и узких (точка), разделенных пробелами. Считывание комбинаций темных линий и светлых пробелов и интерпретация отраженных лучей оказалось работоспособной идеей, на которую впоследствии был получен патент.
Впервые на практике штрихкод был применен выпускником инженерного факультета Массачусетского технологического института, когда тот начал работать на железнодорожной станции и занимался несложной, но рутинной сортировкой вагонов, требующей к тому же постоянного соблюдения точности выполнения операций, недопущения ошибок внесения данных в регистрационные бумаги. Для каждого вагона необходимо выяснить его номер, свериться с сопроводительными документами, уточнить маршрут, определить место в составе и так далее. Эта процедура была достаточно длительной, отнимала много времени и требовала остановки состава.
К середине 20 века технологии уже шагнули вперед, и существовала возможность автоматического считывания достаточно крупных номеров вагонов при помощи фотоэлементов. Но считывание номера, нанесенного в виде арабских цифр, — это достаточно простая задача для человека, знающего, как выглядят цифры, и что они означают. Для машины цифры — это последовательность линий, расположенных под определенным углом. Отсутствие одной или нескольких линий или неточное нанесение делает задачу распознавания цифры (при отсутствии технологии OCR) слабореализуемой. Поэтому было предложено для упрощения машинного распознавания записывать номера не только обычными арабскими “человекочитаемыми” цифрами, но и кодом в виде широких полос синего и красного цвета.
Этот код располагали непосредственно на борту вагона и сделали его достаточно крупным, чтобы фотоэлемент мог выхватывать и безошибочно распознавать ярко освещенный прожектором штрихкод на проходящем мимо стационарного сканера вагона. Испытания подтвердили эффективность работы распознающей системы на скорости до 100 км/ч. Это была уже совершенно работающая технология, полностью изменившая отдельно взятый процесс в целой отрасли.
Позже, с усовершенствованием технологии на смену прожектору пришел лазер, который не только потреблял меньше энергии, чем мощная лампа накаливания, но и позволил сделать наносимые штрихкоды значительно меньше по размеру, а саму сканирующую установку значительно компактнее вплоть до создания ручных и настольных сканеров. Развитие технологий лазерного сканирования и компактизация стала шагом к повсеместному использованию штрихкодов как универсального средства маркировки товаров не только на железнодорожном транспорте.
В конце 60-х годов в США началась разработка универсальной системы нумерации товаров как средства идентификации. Система штрихового кодирования, которую начали применять в торговле, была разработана в 1972 году и получила название UPC — Universal Product Code. Штрихкоды этой системы начали присваивать всем видам товаров, производимым и зарегистрированных в США и Канаде. Одноименная организация начала активную пропаганду и внедрение использования штрихкодов в промышленность и торговлю. Первое историческое считывание штрихкода стандарта UPC в рознице произошло в американском супермаркете в 1974 году.
С 1977 года в Западной Европе для идентификации потребительских товаров стала применяться аналогичная американской система под названием «Европейский артикул» (EAN — European Article Numbering). Сегодня именно эта ассоциация и занимается распределением штрихкодов для производителей товаров. Чтобы избежать дублирования номеров, штрихкоды товарам выдаются централизованно международной ассоциацией, включающей 98 организаций из 100 стран мира. Производитель может получить штрихкод для своего товара, предварительно зарегистрировавшись в этой ассоциации.
Штрихкоды семейств UPC и EAN оперируют достаточно небольшим алфавитом, позволяющим закодировать достаточно ограниченный объем информации. UPC, используемый в США, состоит из 12 символов, EAN — из 13 цифр и является немного усовершенствованной модификацией кода UPC. Кодирующие символы — это вертикальные полосы различной ширины и пробелы между ними. В стандартных линейных кодах зашифрована информация о стране происхождения товара, организации-изготовителе, непосредственно код товара. Для проверки корректности кода в конце размещается контрольная цифра и специальный знак, указывающий на то, что товар производится по лицензии.
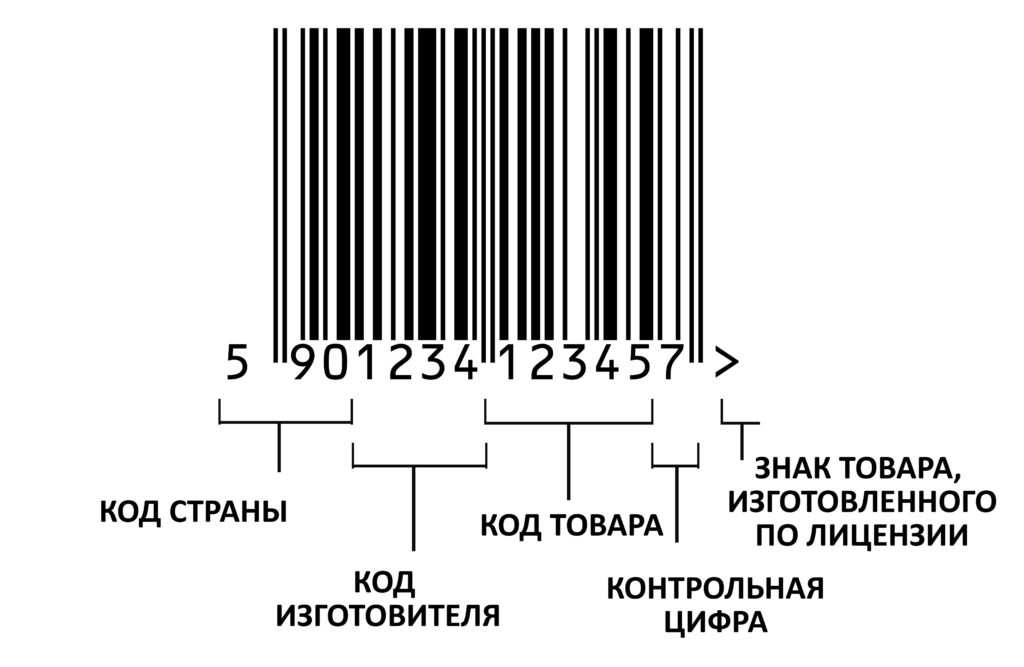
Теперь посмотрим на код с точки зрения структуры и принципов кодирования. Здесь мы подробно разберем только один — стандартизированный — штрихкод типа UPC-A, чтобы показать: принципы кодирования, которые применяются значительно сложнее, чем кажутся на первый взгляд. Эта сложность обеспечивает безошибочность распознавания за счет минимизации риска неверного считывания.

Штрихкод типа UPC-A код разделен на 2 равные части и отображается в виде темных (штрихов) и светлых (пробелов) полос, которые кодируют 12-значный номер UPC-A. Каждая цифра — это уникальный набор из 2 штрихов и 2 пробелов переменной ширины в 1, 2, 3 или 4 модуля (в данном случае — минимальная дискретная ширина полосы). При этом общая ширина кодирующих полос для каждой цифры остается неизменной — 7 модулей. Таким образом, содержательная часть товарного кода UPC-A кодируется в 84 единицах.
Многие задавались вопросом, почему на разных штрихкодах одинаковые цифры могут быть несколькими разными способами (некоторые даже строили на сей счет конспирологические теории). Дело в том, что алгоритм кодирования штрихкода не совсем линейный. В правой и левой частях кода цифры кодируются неодинаково: чередование штрихов и пробелов в цифрах происходит по трем наборам последовательностей (A, B и С). В последовательности А темных модулей всегда нечетное количество, в наборах В и С — четное. При этом набор В — представляет собой инверсию набора а (штрихи заменены пробелами и наоборот), а набор С — зеркальное отражение набора В. Знаки символа в числовых наборах А и В всегда начинаются слева со светлого модуля и заканчиваются справа темным модулем, а в числовом наборе С начинаются слева с темного модуля и заканчиваются справа светлым модулем. В левой стороне при кодировании цифр используются наборы А или В в зависимости от позиции цифры в коде, правая сторона кодируется набором C. Алгоритмы кодирования подробно прописаны в стандартах. Например, в этом.
Кроме полос, кодирующих информацию, графический код содержит ограничительные паттерны начала кода, завершения кода и середину. Концевые паттерны имеют вид штрих-пробел-штрих, а центральный — пробел-штрих-пробел-штрих. Наличие ограничительных паттернов, а также “тихой зоны” вокруг штрихкода позволяет устройству чтения более точно определять границы штрихкода, увеличивая тем самым скорость и точность распознавания.
Форматы штрихкодов постоянно совершенствуются и меняются. На сегодняшний день помимо принятых в международном товарообороте стандартных Universal Product Code и European Article Numbering существует более 300 стандартов штрихкодирования.
С 2005 года принят международный стандарт, в котором используются три основные типа кодирования информации о товарах:
– EAN-8 (сокращённый) — кодируется 8 цифр.
– EAN-13 (полный) — кодируется 13 цифр (12 значащих + 1 контрольная сумма).
– EAN-128 — позволяет кодировать любое количество букв и цифр, объединенных в регламентированные группы.
В отличие от EAN-8 и EAN-13, кодом EAN-128 (GS1-128) используется производителями, перевозчиками и торговыми компаниями для обмена данными о перевозимых грузах. В этом, более длинном коде, может содержаться расширенная информация, такая как номера накладных, индексы пунктов назначения, объемы перевозимого груза, коды товара и серийные номера изделий, сроки годности и пр.
Главное преимуществом штрихкода — это его простота, функциональность и помехозащищенность. Главный недостаток же — относительно малое количество информации, которую с помощью него можно закодировать.
Эра 2-D
С развитием технологий обработки информации, на смену одномерным (линейным) штрихкодам пришли двумерные. Если в линейных (одномерных) кодах используются штрихи, то в двумерных (и многомерных) в качестве элементов кодирования могут выступать уже другие фигуры, поэтому для того чтобы дифференцировать одни от других, здесь будем называть многомерные коды баркодами. Исследования и разработки двумерных кодов начались во многих странах мира в 1980-х годах, так как объема кодируемой в линейных кодах информации оказалось явно недостаточным. Их появление стало естественной эволюцией систем кодирования, и одновременно технологий распознавания, программных и аппаратных возможностей распознающих систем.
Кроме этого, возникала необходимость маркировать кодами буквально все: не только, допустим, узлы агрегатов, но и отдельные детали. Поэтому возникала необходимость миниатюризировать код и повысить плотность кодируемой информации на единицу площади.
В двумерном коде, как и следует из названия, кодирование происходит не по одному направлению, а по двум. Действительно, если расположить несколько одномерных кодов в виде чередующихся фрагментов, получится простейший двумерный код типа Stacked Linear (составной линейный). Если мы “упакуем” модули в квадрат — получится матричный баркод (Matrix).
Пример составного линейного баркода — PDF417, появившийся в 1991 году и запатентованный в 1993. Код PDF417 состоит из строк, образуемых “словами” — набором из чередующихся штрихов и пробелов (4 штриха, 4 пробела — первое число из названия кода). Общая длина каждого слова — 17 модулей (второе число в названии кода).
Помимо собственно содержательных слов, каждая строка состоит из старт-паттерна (крайнего левого набора, ключевых слов (индикаторов — они занимают крайние позиции на строке), необходимых для коррекции ошибок, и стоп-паттерна (Впрочем, существует также и так называемый “усеченный PDF417” (truncated), где исключен индикатор правой строки и уменьшен шаблон остановки до одной линии. Таким образом, усеченные PDF417 занимают меньше места, но они более восприимчивы к неправильному прочтению. Такой вариант PDF417 используют только там, где риск повреждения изображение кода минимальный). Так как все слова имеют одинаковую длину, размещенные одна под другой строки образуют колонки. В самом коде PDF417 как количество строк, так и количество столбцов может варьироваться: код может содержать от 3 до 90 строк, и иметь ширину от 3 до 30 столбцов включительно, не считая столбцов со словами индикаторами. Подробная статья про кодирование PDF417 недавно выходила на Хабре, о возможности его “ручного” декодирования — здесь.

Особенность кода PDF417 заключается в возможности кодировать информацию в текстовом режиме, числовом режиме и режиме данных (байт-режиме).
Так как в PDF417 возросло количество кодируемой информации, для ее корректного считывания и декодирования в коде применены механизмы коррекции ошибок. Это достигается путем добавления ключевых слов, с помощью которых машина может восстановить потерянные или считаные с ошибкой данные. Возможность исправления ошибок является ключевым достоинством PDF417: при распознавании распознающему устройству будут не страшны возможные искажения.
Как и предшественник — линейный штрихкод, PDF417 создавался в тот период, когда мобильные телефоны представляли собой устройства чуть меньше чемодана, а о встроенных камерах, пожалуй, даже не задумывались. Поэтому его использование подразумевало наличие специализированных сканеров, предназначенных для считывания такого кода. Это объясняет сложность данного штрихкода и повышенные требования к разрешению печати.
Баркоды PDF417 широко используются для маркировки медицинских препаратов, наносятся на документы в системах электронного документооборота, применяются на бланках налоговых деклараций и проездных билетов.
Код в матрице
Матричная структура позволяет кодировать информацию как по вертикали, так и по горизонтали, за счет чего объем кодируемых данных значительно увеличивается. Важное преимущество всех матричных кодов заключается в возможности кодировать большой объём информации на очень маленькой площади.
Код Data Matrix
Код Data Matrix был изобретен компанией International Data Matrix в середине 1980-х для программы Space Shuttle, где требовалась маркировка большого количества деталей. Data Matrix был разработан до PDF417, то есть PDF417 не мог предшествовать Data Matrix, как указывается в некоторых источниках. Важное преимущество кода — его компактность и простота нанесения. В настоящее время Data Matrix описывается соответствующими стандартами ISO.

DataMatrix — это двумерный штрихкод, который может хранить до 3116 цифр и до 2335 букв. Информация в баркоде Data Matrix кодируется черными и белыми квадратами (модулями) при этом минимальный линейный размер модуля — 0.255 мм.
Шаблон поиска (finding pattern) в виде буквы «L» — две сплошные линии на внешней стороне кода Data Matrix. Этот шаблон позволяет сканеру штрихкода задать изображению правильную ориентацию и считать информацию в правильном порядке.
Второй важный шаблон, необходимый для понимания кода машиной, — шаблон синхронизации (clocking pattern, clock track). Он необходим для информирования системы считывания о количестве модулей в матрице и для правильного распознавания сетки, на которой размещены модули.
Зона тишины (quiet zone) — это область, отделяющая границу штрихкода от фона и других изображений. Для Data Matrix ширина «зоны тишины» равна линейному размеру используемого модуля. Маленькие габариты для зоны тишины позволяют минимизировать площадь нанесения Data Matrix на поверхность.
Специфика Data Matrix позволяет читать его как в прямом так и отраженном свете (то есть при использовании инвертированного изображения, при котором светлые модули становятся темными).
Еще одно преимущество Data Matrix, что от квадратные модули могут быть заменены на круглые. Это дополнительно расширяет возможности использования различных технологий нанесения, например, в виде тиснения или ударной гравировки. Впрочем, эта же технология замены квадратного модуля на круглый взята на вооружения и в других разновидностях кодов, например, в QR-коде.
Стандартизированный код Data Matrix сегодня рассматривается как ключевое звено идентификации и маркировки фармацевтических товаров и медицинских изделий. С 1 июля 2020 года маркировка кодами Data Matrix станет обязательной для всех лекарств, находящихся в обороте в России.
Подробный процесс создания Data Matrix описан здесь.
Код AZTEC
Баркод типа Aztec появился в 1995 году, как пишут, в результате объединения лучших практик разработки баркодов предыдущих поколений. Вид и структура кода Azteс разработана таким образом, чтобы она была одинаково удобна как для нанесения и считывания. Символы в целом квадратные на квадратной сетке с квадратным центральным “прицелом” из концентрических темных и светлых квадратов типа «яблочка» мишени (в англоязычных описаниях используется термин “bull’s eye”).
Самый маленький символ Aztec Code имеет площадь 15 x 15 модулей, а самый большой — 151 x 151. Самый маленький символ Aztec Code кодирует 13 цифровых или 12 буквенных символов, тогда как самый большой символ Aztec Code кодирует 3832 цифровых или 3067 буквенных символов.

В этом материале мы не ставим своей задачей подробно разбирать каждый код в отдельности, тем более что про Aztec великолепно написано во всех подробностях на Хабре здесь.
QR-код
Добрались до самых, пожалуй, распространенных кодов, которые встречаем на каждом шагу.
QR код это еще одна разновидность матричного кода. Его название происходит от английского «Quick Response» — «Быстрый Отклик». Он был создан компанией Denso-Wave в 1994 году в Японии для внутреннего рынка (отличие QR-кода от других двумерных баркодов в том, что этот код позволяет кодировать символы японского (вернее, пришедшего из Китая в Японию) письма кандзи. Также в QR коде может быть заложена избыточная информация, которая позволяет закодировать определенные действия для программы смартфона или сканера для считывания.
Принципы кодирования QR-кода описаны достаточно подробно и их можно легко найти. Алгоритм того, как читать штрихкод не сканером, а глазами, можно прочитать, например, здесь.
В таком QR-коде можно легко закодировать адрес интернет-страницы, которая будет открываться при наведении на нее мобильного телефона:

А в этом QR-коде содержится не только адрес интернет-страницы, но и номер телефона, адрес электронной почты, почтовый адрес. Для создания карточки контакта достаточно навести на QR-код мобильный телефон, и информация будет автоматически распознана, а данные внесены в систему.

При этом даже наличие логотипа нашей компании, закрывающего около 10% кода, не мешает корректно распознавать всю закодированную информацию.
Ниже пример QR-кода самой большой размерности, который позволяет закодировать до 1852 символов.
Перечисленные баркоды позволяют кодировать цифровые и текстовые данные примерно с одинаковой эффективностью. Согласно сравнению, приведенному на сайте РИТ-сервис, специализирующейся на обработке штрихкодов, QR-код позволяет кодировать большие объёмы цифровых данных на меньшей площади при одинаковом размере модуля по сравнению с Aztec и Data Matrix кодировать большие объёмы цифровых данных. Код Data Matrix уступает QR коду при кодировании более 88 цифр, Aztec уступает QR-коду при кодировании более 170 цифр. Но по эффективности кодирования текста QR-код значительно уступает Aztec, а Data Matrix превосходит только при объёме текста большем 298 символов. Однако, при кодировании текста набранного прописными (заглавными) буквами эффективности QR-код и Aztec близки, а Data Matrix уступает QR-коду уже при кодировании 88 букв.
Что объединяет все эти коды?
Машине важно понимать, что перед ней код, где находится его “начало” и “конец”. Для этого используются “зоны тишины”, специальные пограничные паттерны и “прицелы”. Кроме этого, машине необходимо понимать, в каком формате записаны данные, то есть как производить декодирование — в виде цифр, цифро-буквенного текста, или в формате данных. Машина также должна иметь возможность скорректировать ошибки, чтобы случайное выпадение нескольких пикселов изображения баркода не приводило к его полной нечитаемости. Коррекция ошибок в кодах DataMatrix, Aztec, QR осуществляется с помощью кодов Рида-Соломона, исправляющих ошибки чтения и позволяющие распознавать данные даже в сильно “испорченных” кодах (вплоть до 30% поверхности).
Зачем вообще нужны баркоды?
Баркоды стали настолько привычным явлением, что мы даже не задумываемся о том, зачем они нужны и какую функцию выполняют. И на самом деле, ответ не так очевиден, как кажется. Важно понимать, что баркод относится к средствам автоматизации, то есть обеспечивает коммуникацию между машиной и человеком. Сам по себе баркод не является рабочим инструментом, а представляет ценность лишь при наличии качественной системы распознавания баркодов и интерпретации полученных результатов.
Внедрение системы распознавания баркодов в бизнес-процессы позволяют ускорить поиск, внесение и извлечение информации из баз данных, улучшить логистический контроль, сделать взаимодействие с клиентами более комфортным.
Внедрение баркодов в медицинские карты и внедрение систем распознавания в медицинских учреждениях увеличивает скорость обслуживания пациентов и делает работу регистратуры более системной и упорядоченной.
Внедряемые баркоды на билетах ускоряют прохождение через пункты контроля и турникеты, делая бесконтактную проверку билета более удобным решением, чем физическая проверка контролёром. В этом случае баркод служит элементом защиты от подделки, точно также как и внедряемые баркоды на защищенных полиграфических изделиях и документах строгой отчетности.
Процессы проведения платежей сильно упростились с внедрением баркодов на квитанции оплаты коммунальных услуг, штрафов, налогов и прочих социальных платежей. Все реквизиты оказываются зашифрованными и для проведения платежа в банковском приложении достаточно навести на баркод мобильный телефон, а приложение с модулем распознавания баркодов самостоятельно внесет все реквизиты получателя в нужные поля.
В чем задача и проблемы распознавания баркодов?
Каждый баркод должен быть распознан. Если он не может быть распознан, то из баркода он превращается в нераспознаваемый художественный орнамент.
Три главных задачи, которые необходимо решить при распознавании баркода, — его детектирование, локализация, детектирование битовой матрицы и распознавание. Решению каждой из задач могут помешать разные проблемы, возникающие из за повреждений непосредственно носителя баркода, так и недостатков программно-аппаратных решений.
Детектированию и локализации баркода мешают различные проективные и нелинейные искажения, плохое освещение, блики, ошибки в нанесении. Уровень искажений зависит как от того, как создан баркод, так и от устройства и программного обеспечения, при помощи которых этот баркод считывается. Исходное сообщение кодируется битовой матрицей (из единиц и нулей) по особым правилам (у каждой символогии свои), которая каким-либо образом наносится на носитель. При нанесении обычно единице соответствует темный модуль, а нулю — светлый. Проблема в том, что недостаточно просто локализовать границы кода на носителе, нужно из изображения восстановить оригинальную битовую матрицу. А это сопровождается рядом сложностей, что приводит к наличию специального этапа в чтении кодов.
Как сказано выше, у каждого баркода есть своя степень коррекции ошибок. Даже сильно потертый баркод с высокой степенью коррекции ошибок может быть корректно считан системой. Но при этом сама система при сканировании баркодов должна отличать прилипшую к баркоду песчинку от информационно значимого элемента. Точно также система при считывании должна точно определять границы баркода, устранять возможные искажения, вызванные наклонами, перекосами, оптической деформацией. Особенно это касается двумерных, несущих в себе значительный объем информации.
Важным качеством системы распознавания баркодов является возможность быстро и точно распознавать их под разными углами, при плохой освещенности, вибрациях, тряске, с частично закрытым полем, при наличии бликов и пятен на поверхностях.
А что дальше?
Где два измерения, там 3 и 4. В середине 2006 года Японская компания “Content Idea of ASIA” c гордостью заявила о том, что они изобрели первый в истории 3D-код. В PM-коде (от образовано от “paper memory” — “бумажная память” ) в качестве третьего измерения к двумерному QR-коду был добавлен цвет. Добавление цветной компоненты, по заявлению изобретателя Татсуи Онода, если в черно-белом двумерном QR-коде можно зашифровать 3 кб информации, то в трехмерном — до 720 (то есть в 240 раз больше). Вместо ссылки на изображение, используя топологию цветного 3D-кода, можно зашифровать картинку целиком, а также небольшие видео и аудиофрагменты. Технология получила патенты в Японии и Европе. Судя по всему, проект развивался до 2013 года, а к настоящему моменту заморожен или закрыт. Сайт японской компании-изобретателя не обновляется с 2013 года, а скачать приложение в официальных магазинах приложений уже невозможно. (При желании его можно скачать с некоторых зеркал в сети и на размещенных на сайте разработчика образцах посмотреть, как оно работает).

В 2010 году Microsoft пошла дальше — объявила о создании новой концепции высокоплотных цветных баркодов (High Capacity Color Barcode (HCCB)), где код был представлен уже в виде той же QR-подобной матрицы, однако в качестве элементов кода выступали не черные квадратные модули, а цветные (4 или 8 цветов) треугольники, каждый из которых занимал ⅔ ячейки.

Проект HCCB тоже просуществовал до 2013 года: тогда Microsoft объявила о том, что проект не будет поддерживаться и был закрыт в 2015. Недавно в сети появилась информация о том, что Apple разрабатывает новые типы кодов, которые будут доступны в будущих модификациях ОС. Речь идет о круглых баркодах, где информация кодируется в виде 4-х цветных “капель” размещенных по центру и по периметру круга.
Разумеется, исследования возможности создания и использования цветных баркодов ведутся и сегодня, однако широкого применения пока они не встречают. Причина здесь в том, что при увеличении “измерений” кодировки и росте объема кодируемой информации, растет и количество ошибок, которые требуется исправлять. В цветной код должен быть заложена большая избыточность, необходимая для исправления ошибок, которые обусловлены не только геометрическими, но и хроматическими искажениями, возникающими в процессе отображения штрихкода на носителе (экране, бумаге или любой другой поверхности) и при считывании. Чем выше ожидаемый уровень ошибок, тем большая избыточность должна быть заложена в коде. И как следствие падает плотность кода, что делает процесс его создания, считывания и декодирования экономически нецелесообразным.
Логично предположить, что вслед за кодами с тремя параметрами, последуют четырехмерные коды, динамически изменяющиеся во времени. С точки зрения теории это очень интересные задачи, ставящие вопрос о необходимости одновременной разработки софта, позволяющего распознавать такого рода объекты. И здесь мы подходим к концепции 4D-распознавания, о котором мы расскажем позже.
В качестве послесловия
В 2013 году появилась забавная программа для мобильников Barcode KANOJO, которая декодировала (или делала вид, что декодировала) баркод не совсем привычным способом. Вместо заложенного набора символов на экране мобильного появлялась виртуальная подруга (kanojo) — персонаж аниме — соответствующая просканированному коду. С ней можно было дружить, завоевывать доверие (и любовь???). Проект просуществовал достаточно недолго, персонажи не генерировались а, скорее всего, просто выбирались из некоторого набора созданных заранее с внешнего сервера данных, который сейчас недоступен.
Узнайте больше о программном продукте Smart BarcodeReader и его применении
Smart BarcodeReader
Smart Code Engine
Скачайте мобильное демоприложение и попробуйте нашу технологию распознавания Smart BarcodeReader в действии
Блог
26.03.2026Какие технологии необходимы в финтехе в 2026 году помимо распознавания паспорта
17.03.2026Распознавание паспорта: научный подход к автоматизации бизнеса
26.02.2026Распознавание в миниаппах: как добавить ИИ для ежедневного банкинга в мессенджеры
Все статьи »
Заказать продукт
Быстрая интеграция технологии распознавания документов в бизнес-процессы вашей компании
