






Система Smart Engines с точностью до 99,9% распознает полный спектр документов юридических лиц и ИП, включая регистрационные, учредительные, финансовые, бухгалтерские и отчетные документы. Алгоритмы ИИ построены на научных принципах достоверности и интерпретируемости — по каждому извлеченному символу можно получить численную оценку уверенности.
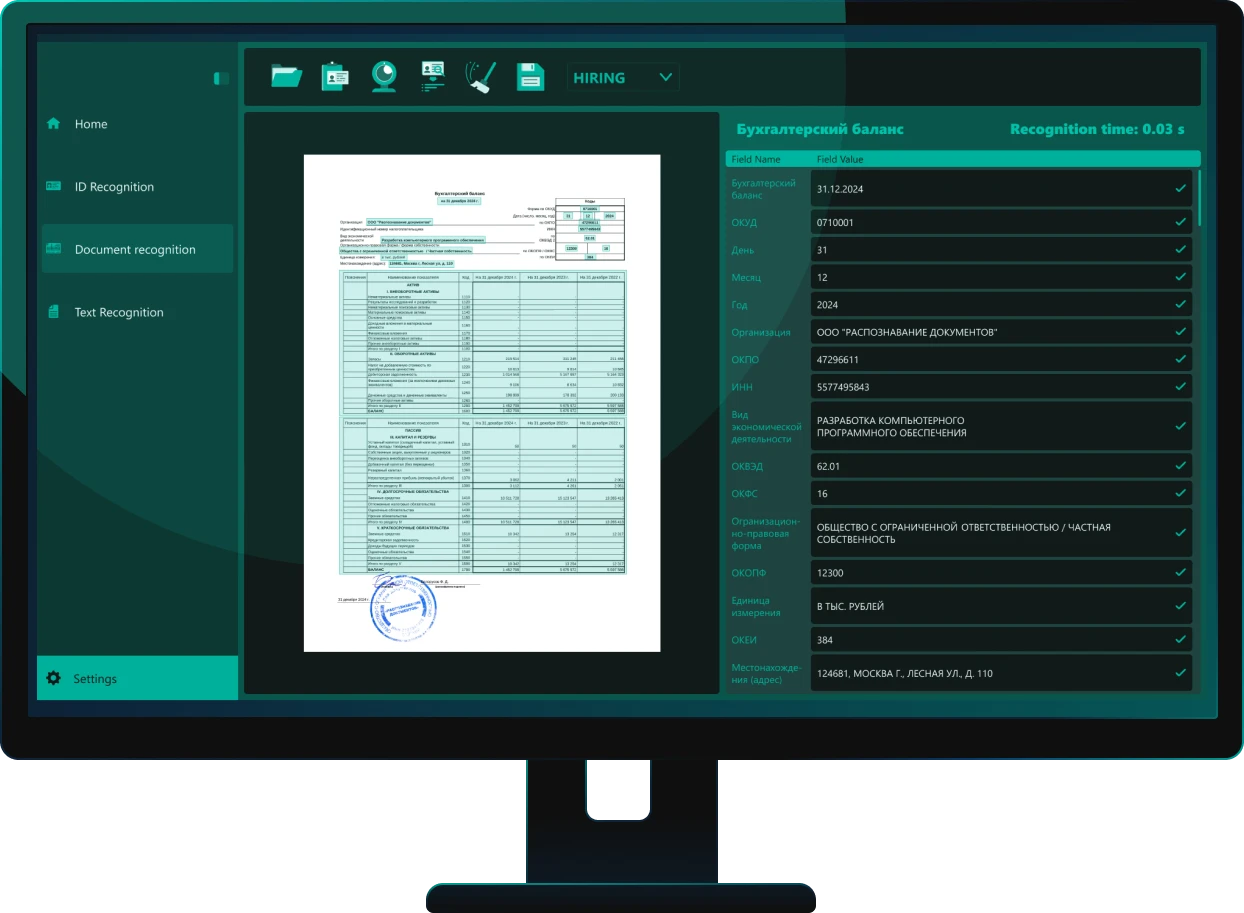
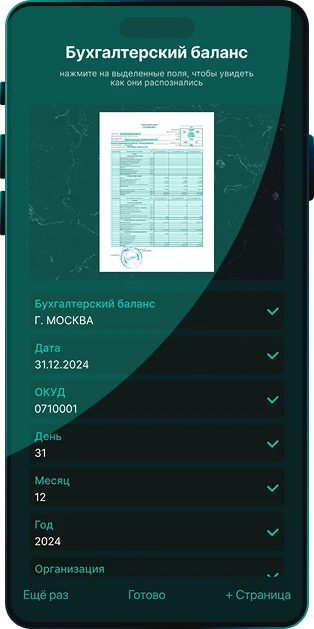
Решение Smart Engines автоматизирует распознавание финансовой и бухгалтерской отчетности и других документов, необходимых для кредитного скоринга и принятия решений. ИИ извлекает данные из более чем 80 преднастроенных шаблонов российский документов, включая бухгалтерский баланс, налоговые декларации и отчеты о движении денежных средств.
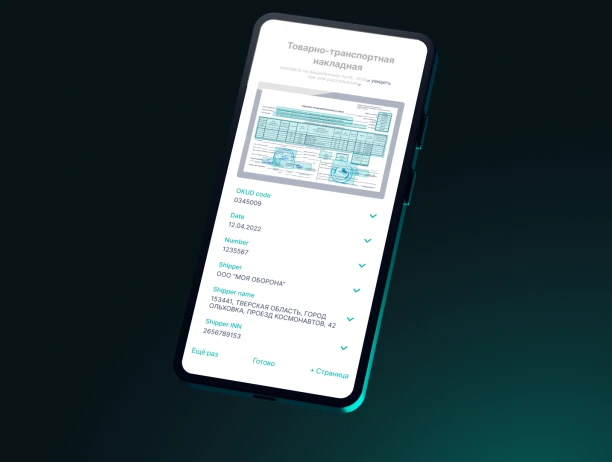
ИИ Smart Engines помогает построить кредитный конвейер и создать единую точку ввода данных из любых кредитных документов вне зависимости от типа. Система автоматически находит и классифицирует документы на фото и сканах и распознает даже многостраничные формы.
Система Smart Engines является мультиплатформенным программным продуктом, доступным на любых устройствах. Решение интегрируется на сервера, десктопы и мобильные устройства, включая смартфоны и планшеты. Благодаря модулю WebAssembly распознавание также можно запустить в браузере и мини-приложениях мессенджеров.
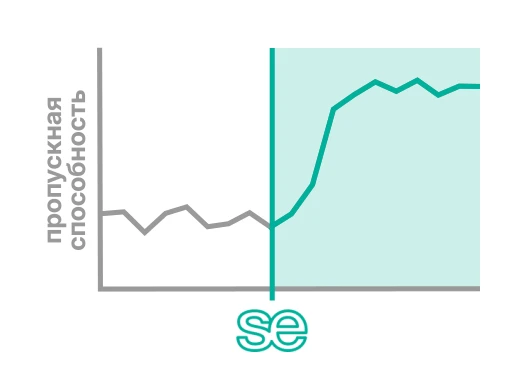
Система Smart Engines снимает до 100% нагрузки банка в части ввода и проверки данных из бумажных документов и поступающих по ЭДО сканов. Это позволяет снять операционные барьеры, повысить пропускную способность кредитного конвейера, а также исключить ошибки человеческого фактора.
Технология Smart Engines масштабируется под любые объемы бизнеса без усложнения операционных процессов и ИТ-ландшафта. Система обрабатывает до 600 тысяч страниц в сутки на одном сервере и до 16 млн страниц на кластере без использования графических процессоров (GPU). Даже в пиковых нагрузках решение обеспечивает непревзойденное качество и высочайшую скорость извлечения данных.
Система Smart Engines с высокой точностью распознает печатные, рукопечатные и рукописные реквизиты в документах вне зависимости от шрифта, начертания и почерка. ИИ мгновенно извлекает надписи и пометки, сделанные с помощью любых пишущих инструментов. Алгоритмы ИИ распознают даже сложные и трудночитаемые рукописные слова — без использования словарей и языковых моделей.
Решение Smart Engines извлекает данные из документов, снятых при любых условиях, и не требует идеального ракурса съемки. Качество распознавания остается высоким даже при зашумленности изображения, неравномерном освещении и произвольных углах наклона документа в кадре. Это позволяет использовать систему для надежного ввода данных кредитных документов в мобильных сценариях.
Система Smart Engines работает локально в ИТ-инфраструктуре заказчика (on-premise). В процессе обработки изображения и данные из документов не покидают защищенный контур банка и не отправляются на внешние сервера и в облачные сервисы. Решение не требует интернет-соединения, не использует графические вычислительные ресурсы и краудсорсинг. Это обеспечивает полную конфиденциальность обработки данных.
Как работает распознавание для кредитного конвейера
Система распознает регистрационные документы ИП и ЮЛ, финансовую и бухгалтерскую отчетность, кредитные анкеты и иные материалы заемщика. Извлечение реквизитов выполняется из фото, сканов и PDF, включая изображения низкого качества. Система распознает тексты, таблицы, отметки, штрихкоды. Обеспечивается высокоточное распознавание печатного, рукописного и смешанного текста. Обучение системы на исключительно синтетических данных позволяет избежать лингвистических галлюцинаций в задачах высокой ответственности. Система автоматически классифицирует документы и проверяет правильность их оформления. ПО работает полностью в контуре заказчика, на смартфонах, в вебе, PWA, десктопе и на сервере, обеспечивает производительность до 16 млн страниц в сутки без GPU.
Возможности распознавания
- Быстрый ввод документов в кредитный конвейер даже при низком качестве фото и сканов
- Распознавание документов заемщика на смартфоне для ускорения старта кредитной заявки
- Веб-компонента PWA для распознавания документов в онлайн-каналах банка
- Автоматическая классификация документов во входящем потоке кредитных заявок
- Обработка многостраничных кредитных досье, финансовых и корпоративных документов в одном потоке
- Распознавание учредительных, корпоративных и распорядительных документов, включая рукописные документы и пометки
- Автоматическое извлечение реквизитов, сумм, таблиц, отметок, чекбоксов и штрихкодов из кредитных документов
- Контроль наличия и цвета подписей и печатей для верификации и проверки документов
- Распознавание штампов ЭЦП в документах, поступающих в кредитный контур
- Выявление признаков цифровой подделки изображения документа
- Контроль целостности и корректности данных до передачи в скоринговые и учетные системы
- Высокая производительность на CPU без затрат на GPU-инфраструктуру
- Собственная технология GreenOCR® для быстрого и точного извлечения данных
- Мгновенный поиск и распознавание данных за счет специализированных 4.6-битных нейросетей
- Потоковая обработка до 420 страниц в минуту на сервере в защищенном on-premise-контуре
- Устойчивое распознавание рукописи независимо от почерка
- Поддержка полностью рукописных документов
- Распознавание без лингвистических галлюцинаций для критически важных кредитных сценариев
- Поддержка документов для процедур ПОД/ФТ и compliance-проверок в составе кредитного процесса
- Конструктор шаблонов распознавания для распознавания кредитных анкет по форме банка
- Автоматическое определение типа документа
Какие документы
распознаются
Возможности
интеграции
DocEngine engine = DocEngine.Create(<PATH_TO_CONFIGURATION_FILE>, true);
DocSessionSettings settings = engine.CreateSessionSettings();
settings.SetCurrentMode("primary_accounting");
settings.AddEnabledDocumentTypes("*");
DocSession session = engine.SpawnSession(settings, <PERSONALIZED_SIGNATURE>);
DocProcessingSettings proc_settings = session.CreateProcessingSettings();
Image image = Image.FromFile(<PATH_TO_IMAGE>);
session.ProcessImage(image, proc_settings);
DocResult result = session.GetCurrentResult();
Document document = result.DocumentsBegin().GetDocument();
for (DocTextFieldsIterator iterator = doc.TextFieldsBegin(); !iterator.Equals(doc.TextFieldsEnd()); iterator.Advance()) {
String name = iterator.GetField().GetBaseFieldInfo().GetName();
String value = iterator.GetField().GetOcrString().GetFirstString().GetCStr();
}
std::unique_ptr<se::doc::DocEngine> engine(se::doc::DocEngine::Create(<PATH_TO_CONFIGURATION_FILE>, true));
std::unique_ptr<se::doc::DocSessionSettings> settings(engine->CreateSessionSettings());
settings->SetCurrentMode("primary_accounting");
settings->AddEnabledDocumentTypes("*");
std::unique_ptr<se::doc::DocSession> session(engine->SpawnSession(*settings, <PERSONALIZED_SIGNATURE>));
std::unique_ptr<se::doc::DocProcessingSettings> proc_settings(session->CreateProcessingSettings());
std::unique_ptr<se::common::Image> image(se::common::Image::FromFile(<PATH_TO_IMAGE>));
session->ProcessImage(*image, proc_settings.get());
const se::doc::DocResult& result = session->GetCurrentResult();
const se::doc::Document& doc = result.DocumentsBegin().GetDocument();
for (auto iterator = doc.TextFieldsBegin(); iterator != doc.TextFieldsEnd(); ++iterator) {
std::string name = iterator.GetFieldPtr()->GetBaseFieldInfo().GetName();
std::string value = iterator.GetFieldPtr()->GetOcrString().GetFirstString().GetCStr();
}
DocEngine engine = DocEngine.Create(<PATH_TO_CONFIGURATION_FILE>, true);
DocSessionSettings settings = engine.CreateSessionSettings();
settings.SetCurrentMode("primary_accounting");
settings.AddEnabledDocumentTypes("*");
DocSession session = engine.SpawnSession(session_settings, <PERSONALIZED_SIGNATURE>);
DocProcessingSettings proc_settings = session.CreateProcessingSettings();
Image image = Image.FromFile(<PATH_TO_IMAGE>);
session.ProcessImage(image, proc_settings);
DocResult result = session.GetCurrentResult();
doc_it = recog_result.DocumentsBegin()
Document doc = recog_result.DocumentsBegin().GetDocument();
for (DocTextFieldsIterator iterator = doc.TextFieldsBegin(); !iterator.Equals(doc.TextFieldsEnd()); iterator.Advance()) {
String name = iterator.GetField().GetBaseFieldInfo().GetName();
String value = iterator.GetField().GetOcrString().GetFirstString().GetCStr());
}
engine = pydocengine.DocEngine.Create(<PATH_TO_CONFIGURATION_FILE>)
settings = engine.CreateSessionSettings()
settings.SetCurrentMode("primary_accounting")
settings.AddEnabledDocumentTypes("*")
session = engine.SpawnSession(settings, <PERSONALIZED_SIGNATURE>)
proc_settings = session.CreateProcessingSettings()
image = pydocengine.Image.FromFile(<PATH_TO_IMAGE>)
session.ProcessImage(image, proc_settings)
result = session.GetCurrentResult()
doc_it = recog_result.DocumentsBegin()
doc = recog_result.DocumentsBegin().GetDocument()
iterator = doc.TextFieldsBegin()
while(iterator != doc.TextFieldsEnd()):
name = iterator.GetField().GetBaseFieldInfo().GetName()
value = iterator.GetField().GetOcrString().GetFirstString().GetCStr()
iterator.Advance()
Уверенность распознавания, координаты объектов, вырезание полей и документов
Возврат зоны принятия решения для проверок подлинности

Попробуйте качество наших технологий
- Скачайте мобильное демо-приложение, в котором все возможности собраны воедино
- Можно на время отключить интернет, чтобы убедиться, что изображения и ваши данные не передаются
- Извлекайте данные паспортов, удостоверений личности и других документов. Пробуйте распознавать оригиналы и копии при различных условиях съемки.



Заказать продукт
Часто задаваемые вопросы
Какие документы юридических лиц и ИП поддерживает система?
Система распознает полный спектр документов юридических лиц и ИП, необходимых в рамках кредитного процесса. Среди них — ЕГРЮЛ, ЕГРИП, уставы и учредительные договоры, удостоверения личности бенефициарных владельцев и руководителей компании и другие документы. В общей сложности система поддерживает более 80 преднастроенных шаблонов российских регистрационных, учредительных, финансовых, бухгалтерских и отчетных документов.
Может ли решение распознать рукописный текст?
Да. Помимо печатных реквизитов кредитных документов решение распознает рукопечатные и рукописные поля с точностью до 99,9%. Программный продукт извлекает даже трудноразборчивый текст, написанный ручкой, карандашом или пером. Поддерживается распознавание любых букв, цифр и их комбинаций, включая сложные и трудночитаемые слова (например, со схожими символами «ш», «л», «и», «п»), без использования словарей и языковых моделей.
Распознает ли система даты, суммы и графические элементы?
Да. Система автоматически анализирует структуру и извлекает 100% ключевой информации из документов: даты, суммы, наименования, номенклатуру, ставки НДС и другие сведения. Алгоритмы искусственного интеллекта распознают любые графические элементы, включая сложные табличные формы, печати и подписи. Пользователь получает готовые структурированные данные в удобном редактируемом формате.
Как решение помогает автоматизировать кредитный конвейер?
Решение сокращает время обработки документов до 50 раз и повышает точность извлечения данных в среднем в 1,5 раза по сравнению с ручным вводом. Это позволяет снять операционные барьеры, связанные с ручным переносом данных, повысить пропускную способность кредитного конвейера и повысить качество данных в учетных системах компании.
Можно ли добавить распознавание новых видов документов — внутрикорпоративных форм, анкет и опросников?
Да. Для настройки шаблонов внутрикорпоративных форм, анкет и опросников предусмотрен дизайнер форм со встроенным ИИ-агентом. Он позволяет в реальном времени добавлять любые новые пользовательских документов без привлечения программистов и обращения к вендору. Достаточно загрузить один пример документа — система автоматически определит структуру, выделит ключевые элементы и создаст шаблон для распознавания.
Каковы требования к качеству изображения?
Система нетребовательна к условиям съемки и позволяет с точностью до 99,9% извлекать данные с фотографий и сканов документов даже при наличии шумов, теней и проективных искажений документа на изображении. Это позволяет применять решение в мобильных сценариях ввода данных кредитных документов.
Поддерживается ли потоковая обработка документов?
Да. Система способна обрабатывать большие объемы документов в потоковом режиме и автоматически интегрировать их содержимое в целевые процессы и системы. Система автоматически классифицирует документы, извлекает данные и передает их в учетные системы без участия человека, обеспечивая обработку любых документов в реальном времени.
На каких устройствах и платформах работает система?
Программный продукт бесшовно интегрируется в серверные, десктопные, мобильные и веб-приложения. Все вычисления осуществляются полностью локально: непосредственно на устройстве пользователя (on-device) или на собственных серверах в защищенном контуре (on-premise). Это обеспечивает полную независимость от пользовательских платформ и внешней инфраструктуры.
Использует ли система облака или внешние серверы для хранения и обработки данных?
Нет. Система является on-premise решением, работающим полностью локально в защищенном контуре пользователя. В процессе обработки данные и изображения документов не отправляются на внешние облачные сервисы или краудсорсинговые платформы. Это гарантирует высокий уровень безопасности обработки конфиденциальной информации и персональных данных.
Возможна ли интеграция с учетными системами (1С, ERP)?
Да. Программный продукт бесшовно интегрируется с 1С и ERP-системами, позволяя автоматически передавать извлеченные данные в целевые процессы без доработок и усложнения текущих операций. Интеграция выполняется через REST API или другие стандартные интерфейсы, а результаты распознавания моментально поступают в корпоративные системы без необходимости ручных корректировок.