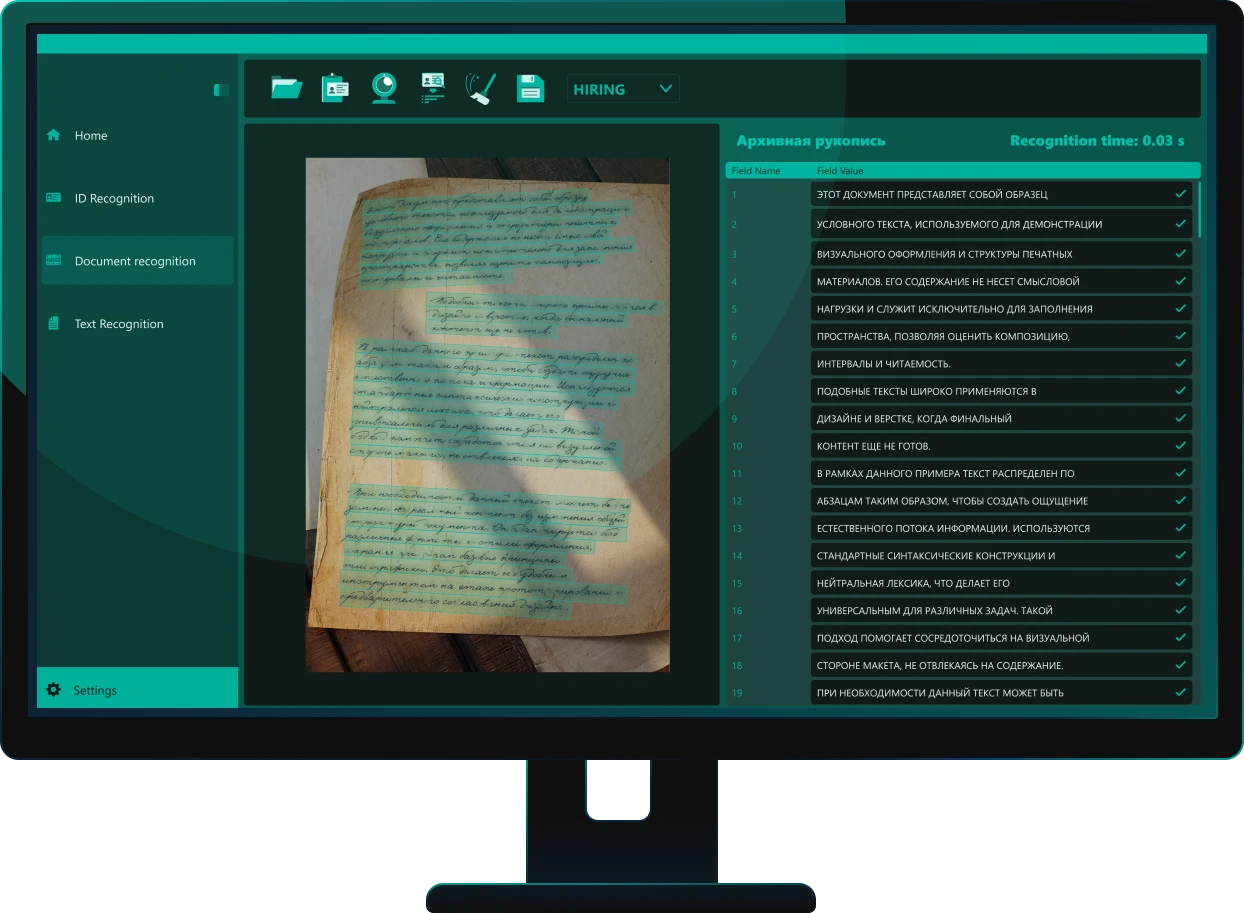







Система Smart Engines обеспечивает высокоскоростную оцифровку больших массивов бумажных документов в автоматическом режиме. Распознанный текст становится доступным для полнотекстового поиска по всему массиву документов, что позволяет быстро находить нужную информацию по словам и фразам без ручного просмотра архивов.
ИИ Smart Engines автоматически удаляет зачеркивания и восстанавливает исходный текст в документах с использованием специализированной нейросети. Решение корректно обрабатывает исправления, наложения и перекрытия, позволяя получить исходные данные без визуальных помех и искажений.
Алгоритмы Smart Engines обеспечивают распознавание документов любого качества, включая старые, выцветшие и поврежденные. Алгоритмы анализа изображений и нейросетевые модели позволяют извлекать данные при низком контрасте, наличии разрывов, пятен и других артефактов.
Система Smart Engines применяет современные алгоритмы бинаризации для выделения текста на изображениях исторических документов любой сложности. Решение учитывает глобальный контекст изображения и корректно отделяет текст от фона даже при неравномерном освещении, выцветании, шуме и сложной структуре бумаги.
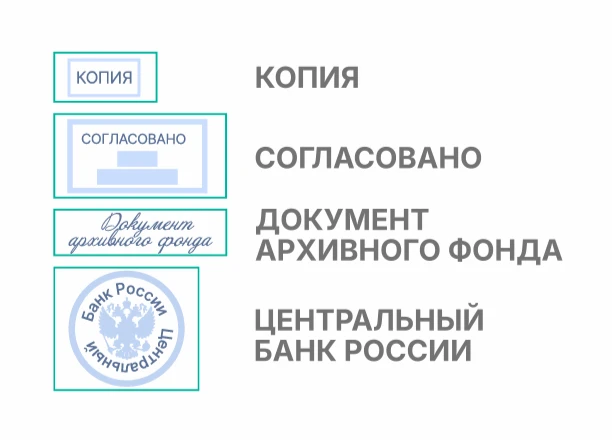
Система Smart Engines обеспечивает автоматическое распознавание рукописных записей, штампов, печатей и архивных отметок на документах. Решение извлекает текст и ключевые атрибуты, включая содержимое штампов и печатей, даже при наложении на основной текст, частичном перекрытии и различном качестве изображения.
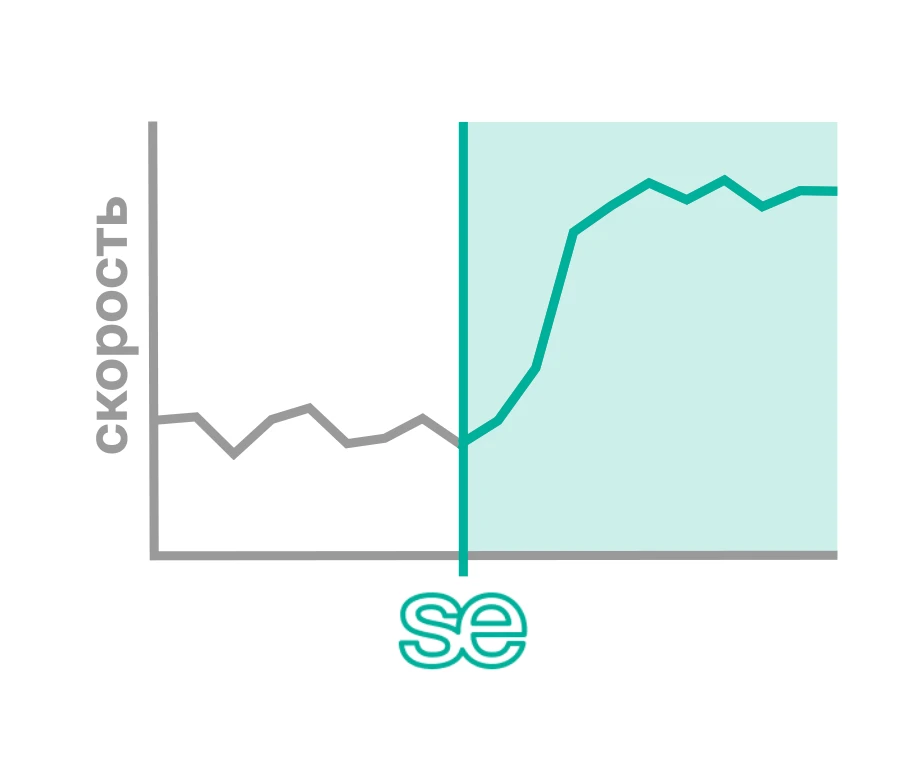
Решение Smart Engines обеспечивает высокоскоростную обработку больших объемов архивных документов в автоматическом режиме. ИИ распознает и извлекает данные из документов в потоковом формате, позволяя обрабатывать десятки страниц в секунду без использования GPU. Поддерживается работа с разнородными типами и форматами архивных материалов, что делает возможной массовую оцифровку и обработку документов без ручного ввода.
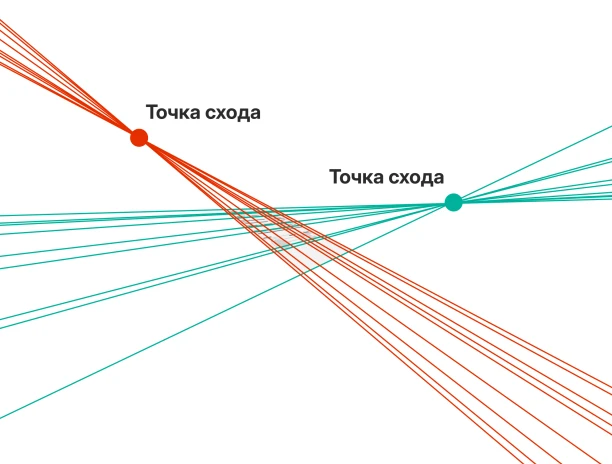
Система Smart Engines применяет нейросетевые архитектуры, основанные на преобразовании Хафа, для автоматического выравнивания изображений документов. Такой подход позволяет надежно выявлять геометрию документа — линии, границы и структуру — даже при сильных искажениях, наклонах и частичной утрате данных. Это существенно повышает точность последующего извлечения данных.
ИИ Smart Engines обеспечивает обработку документов в различных форматах — от сканов и фотографий до многостраничных PDF-файлов. Решение автоматически обрабатывает каждую страницу документа, извлекая текст и данные вне зависимости от структуры и качества исходного документа. Поддерживается работа с объемными многостраничными документами, где информация распределена по десяткам и сотням страниц, что особенно важно для архивных и юридических документов.
Система Smart Engines работает локально в ИТ-инфраструктуре заказчика (on-premise). В процессе обработки изображения и данные из документов не покидают защищенный контур и не отправляются на внешние сервера и в облачные сервисы. Решение не требует интернет-соединения, не использует графические вычислительные ресурсы и краудсорсинг. Это обеспечивает полную конфиденциальность обработки данных.
Как работает распознавание архивов
ПО предназначено для оцифровки исторических архивов и перевода бумажных фондов в цифровой формат с возможностью полнотекстового поиска. Система работает со сканами, фотографиями и многостраничными PDF, распознает старые, выцветшие и поврежденные документы, рукописные пометки, штампы, печати и зачеркнутые фрагменты. Для повышения качества используются state-of-the-art методы бинаризации, Хаф-сети для выравнивания и нейросети для анализа сложных архивных образцов. Решение формирует текстовый слой, возвращает геометрию и альтернативы распознавания, поддерживает редкие языки и специальные шрифты. ПО работает полностью в контуре заказчика, не требует GPU и обеспечивает высокопроизводительную потоковую обработку больших архивных массивов.
Возможности распознавания
- Распознавание сканов и фотографий низкого качества
- Поиск, выравнивание и нормализация документа на фотографии
- GreenOCR® — экологичный искусственный интеллект распознавания текста
- Уникальные 4.6 битные нейросетевые модели для скоростного распознавания на CPU
- Распознавание силами CPU, не требует ресурсов GPU и NPU
- Распознавание рукописных текстов, надписей и пометок вне зависимости от почерка
- Новаторские малобитные и компактные нейросетевые модели
- Распознавание печатной и рукописной кириллической письменности
- Высокоточный OCR для всех языков, базирующихся на латинице
- Распознавание арабского, японского, корейского и китайского языков
- Распознавание иврита, греческого, грузинского и армянского
- Распознавание многостраничных документов
- Поиск и распознавание таблиц
- Потоковое распознавание в контуре (on-premise) со скоростью более 100 тысяч страниц в час на сервере без GPU
- Надежное распознавание рукописи и печатного текста без лингвистических галлюцинаций
- AI модели обучены исключительно на синтетических данных
- Возврат геометрии текстов и символов
- Возврат альтернатив распознавания каждого символа
- Формирование текстового слоя для полнотекстового поиска по архиву
- Повышение читаемости выцветших и слабоконтрастных архивных материалов
- Обработка сложного фона, пятен, теней и артефактов старых документов
- Нейросеть для анализа зачеркнутых фрагментов документа
- Работа с низкокачественными архивными образцами
- Возможность дообучения нейросетей специальным шрифтам
- Возможность дообучения нейросетей редким языкам
- Автоматическое определение типа документа
Какие документы
распознаются
Возможности
интеграции
DocEngine engine = DocEngine.Create(<PATH_TO_CONFIGURATION_FILE>, true);
DocSessionSettings settings = engine.CreateSessionSettings();
settings.SetCurrentMode("primary_accounting");
settings.AddEnabledDocumentTypes("*");
DocSession session = engine.SpawnSession(settings, <PERSONALIZED_SIGNATURE>);
DocProcessingSettings proc_settings = session.CreateProcessingSettings();
Image image = Image.FromFile(<PATH_TO_IMAGE>);
session.ProcessImage(image, proc_settings);
DocResult result = session.GetCurrentResult();
Document document = result.DocumentsBegin().GetDocument();
for (DocTextFieldsIterator iterator = doc.TextFieldsBegin(); !iterator.Equals(doc.TextFieldsEnd()); iterator.Advance()) {
String name = iterator.GetField().GetBaseFieldInfo().GetName();
String value = iterator.GetField().GetOcrString().GetFirstString().GetCStr();
}
std::unique_ptr<se::doc::DocEngine> engine(se::doc::DocEngine::Create(<PATH_TO_CONFIGURATION_FILE>, true));
std::unique_ptr<se::doc::DocSessionSettings> settings(engine->CreateSessionSettings());
settings->SetCurrentMode("primary_accounting");
settings->AddEnabledDocumentTypes("*");
std::unique_ptr<se::doc::DocSession> session(engine->SpawnSession(*settings, <PERSONALIZED_SIGNATURE>));
std::unique_ptr<se::doc::DocProcessingSettings> proc_settings(session->CreateProcessingSettings());
std::unique_ptr<se::common::Image> image(se::common::Image::FromFile(<PATH_TO_IMAGE>));
session->ProcessImage(*image, proc_settings.get());
const se::doc::DocResult& result = session->GetCurrentResult();
const se::doc::Document& doc = result.DocumentsBegin().GetDocument();
for (auto iterator = doc.TextFieldsBegin(); iterator != doc.TextFieldsEnd(); ++iterator) {
std::string name = iterator.GetFieldPtr()->GetBaseFieldInfo().GetName();
std::string value = iterator.GetFieldPtr()->GetOcrString().GetFirstString().GetCStr();
}
DocEngine engine = DocEngine.Create(<PATH_TO_CONFIGURATION_FILE>, true);
DocSessionSettings settings = engine.CreateSessionSettings();
settings.SetCurrentMode("primary_accounting");
settings.AddEnabledDocumentTypes("*");
DocSession session = engine.SpawnSession(session_settings, <PERSONALIZED_SIGNATURE>);
DocProcessingSettings proc_settings = session.CreateProcessingSettings();
Image image = Image.FromFile(<PATH_TO_IMAGE>);
session.ProcessImage(image, proc_settings);
DocResult result = session.GetCurrentResult();
doc_it = recog_result.DocumentsBegin()
Document doc = recog_result.DocumentsBegin().GetDocument();
for (DocTextFieldsIterator iterator = doc.TextFieldsBegin(); !iterator.Equals(doc.TextFieldsEnd()); iterator.Advance()) {
String name = iterator.GetField().GetBaseFieldInfo().GetName();
String value = iterator.GetField().GetOcrString().GetFirstString().GetCStr());
}
engine = pydocengine.DocEngine.Create(<PATH_TO_CONFIGURATION_FILE>)
settings = engine.CreateSessionSettings()
settings.SetCurrentMode("primary_accounting")
settings.AddEnabledDocumentTypes("*")
session = engine.SpawnSession(settings, <PERSONALIZED_SIGNATURE>)
proc_settings = session.CreateProcessingSettings()
image = pydocengine.Image.FromFile(<PATH_TO_IMAGE>)
session.ProcessImage(image, proc_settings)
result = session.GetCurrentResult()
doc_it = recog_result.DocumentsBegin()
doc = recog_result.DocumentsBegin().GetDocument()
iterator = doc.TextFieldsBegin()
while(iterator != doc.TextFieldsEnd()):
name = iterator.GetField().GetBaseFieldInfo().GetName()
value = iterator.GetField().GetOcrString().GetFirstString().GetCStr()
iterator.Advance()
Уверенность распознавания, координаты объектов, вырезание полей и документов
Возврат зоны принятия решения для проверок подлинности

Попробуйте качество наших технологий
- Скачайте мобильное демо-приложение, в котором все возможности собраны воедино
- Можно на время отключить интернет, чтобы убедиться, что изображения и ваши данные не передаются
- Извлекайте данные паспортов, удостоверений личности и других документов. Пробуйте распознавать оригиналы и копии при различных условиях съемки.


