







Система Smart Engines формирует высокоточный текстовый вывод, оптимизированный для обработки большими языковыми моделями (LLM). Технология возвращает весь оцифрованный текст без искажений и потери исходной структуры, что позволяет значительно повысить качество данных для ИИ-агентов и упростить интеграцию с AI-системами.
Технология Smart Engines обеспечивает омнифонтовое распознавание текста более чем на 100 языках мира независимо от гарнитуры, начертания и качества печати. Система одинаково эффективно работает с латиницей, кириллицей, арабской вязью, китайскими и японскими иероглифами, корейским письмом и другими сложными системами письменности.
Система Smart Engines использует наиболее передовые нейросетевые алгоритмы для поиска и локализации текста на изображениях документов любой сложности. Искусственный интеллект с высочайшей точностью определяет текстовые области и извлекает данные даже на низкокачественных сканах и фотографиях, включая изображения с артефактами сканирования, шумами, перекосами, тенями и сложным фоном.
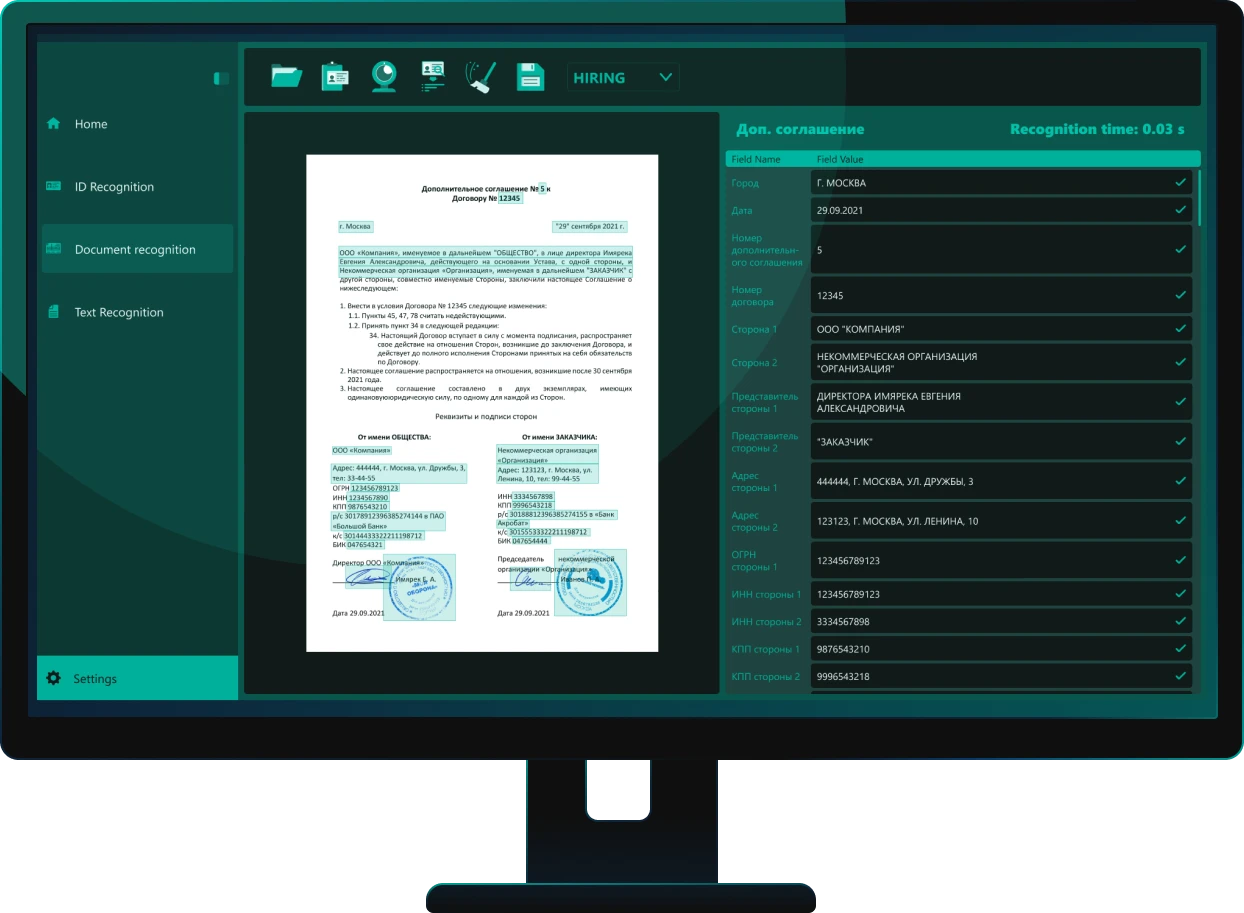
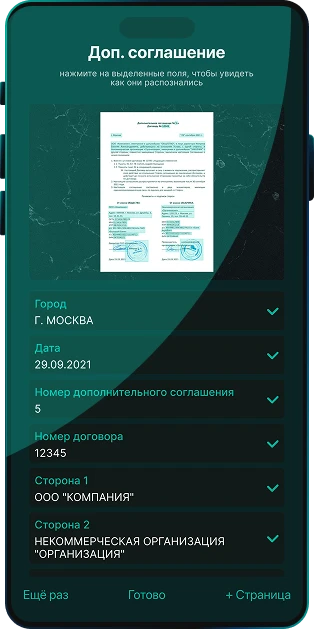
Система автоматически определяет тип документа на фото и сканах и извлекает ключевые реквизиты из деловых документов РФ и документов, удостоверений личности всего мира. Технология Smart Engines поддерживает потоковую обработку больших массивов документов, ускоряя ввод данных, проверку и автоматизацию бизнес-процессов.
Искусственный интеллект извлекает любой печатный, рукописный и смешанный текст, включая трудноразборчивый почерк и пометки, сделанные от руки. Для последующей обработки NLP-моделями система возвращает знакоместа, альтернативы и всю геометрию, позволяя строить высокоточные сценарии анализа, обработки и принятия решений с помощью ИИ-агентов.
Система Smart Engines обеспечивает сверхбыструю обработку документов — до 1800 страниц в минуту на одном сервере без использования GPU. Архитектура решения позволяет масштабировать технологию под любые объемы нагрузки без усложнения существующей ИТ-инфраструктуры, обеспечивая максимальную производительность и минимальные затраты на вычислительные ресурсы.
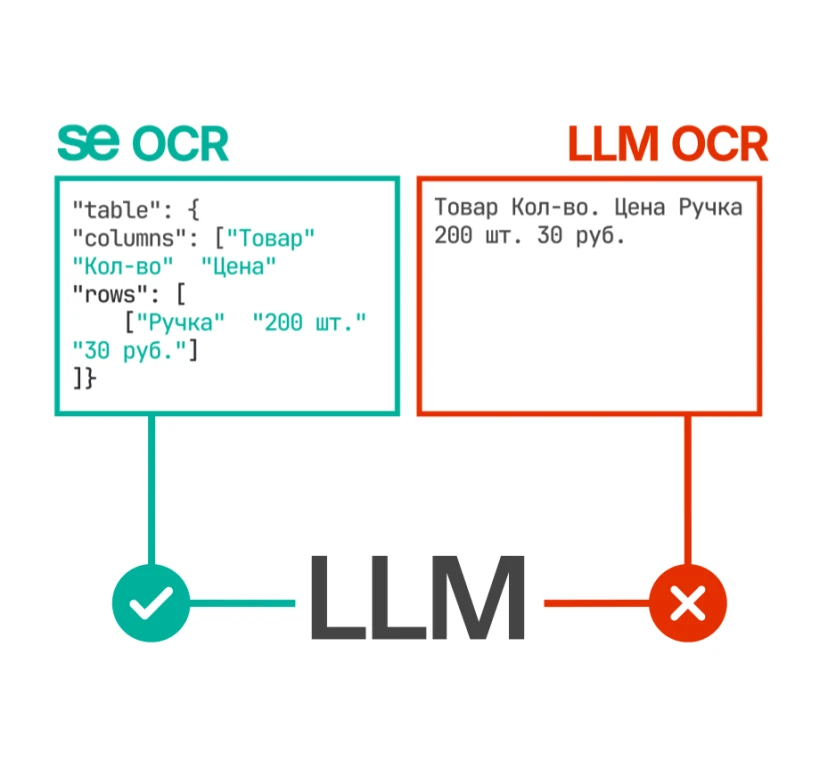
Система извлекает весь текст и реквизиты из документов в исходном виде «as is» — без интерпретации и вмешательства в исходные данные. В отличие от LLM, склонных к галлюцинациям, искусственный интеллект Smart Engines обеспечивает точное и проверяемое распознавание, необходимое для юридически значимых и бизнес-критичных процессов.
Технология Smart Engines с высочайшей точностью распознает документы, снятые в условиях реальной жизни: при плохом освещении, сложном фоне, размытии, перекосах, бликах и низком разрешении. Алгоритмы искусственного интеллекта устойчивы к артефактам на фотографиях и сканах, обеспечивая нормализацию и точное извлечение данных даже в случаях, где не справляются традиционные OCR-инструменты.
Решение обрабатывает документы полностью локально внутри инфраструктуры заказчика без передачи данных во внешние сервисы. Это защищает конфиденциальную информацию от неавторизованного доступа и утечек, а также обеспечивает полное соответствие требованиям ИБ и законодательства в области обработки данных.
Как работает распознавание для ИИ‑агентов
Надежное и точное распознавание текстов для создания ИИ-агентов на базе LLM‑моделей, где критически важна полнота, скорость и особенно достоверность данных. Система распознает печатный текст на 100+ языках, включая арабский, китайский, японский и корейский, кириллический, рукописный и смешанный тексты. Для результатов распознавания возвращает знакоместа, альтернативы и всю геометрию. ПО работает с фото и сканами низкого качества. Поддерживается поиск, выравнивание и нормализация документа, распознавание таблиц и многостраничных файлов, классификация документов и выделение реквизитов. Решение работает автономно в контуре заказчика, не требует GPU, обрабатывает до 1800 страниц в минуту на сервере.
Возможности распознавания
- Распознавание сканов и фотографий низкого качества
- Поиск, выравнивание и нормализация документа на фотографии
- Распознавание документа А4 на смартфоне за 2-3 секунды
- GreenOCR® — экологичный искусственный интеллект распознавания текста
- Уникальные 4.6-битные нейросетевые модели для скоростного распознавания на CPU
- Распознавание силами CPU, не требует ресурсов GPU и NPU
- Высокоточное распознавание текста на фото и скане
- Распознавание рукописных текстов, надписей и пометок вне зависимости от почерка
- Новаторские малобитные и компактные нейросетевые модели
- Распознавание печатной и рукописной кириллической письменности
- Высокоточный OCR для всех языков, базирующихся на латинице
- Распознавание арабского, японского, корейского и китайского языков
- Распознавание иврита, греческого, грузинского и армянского
- Распознавание многостраничных документов
- Поиск и распознавание таблиц
- Потоковое распознавание в контуре (on-premise) со скоростью более 100 тысяч страниц в час на сервере без GPU
- Надежное распознавание рукописи и печатного текста без лингвистических галлюцинаций
- AI модели обучены исключительно на синтетических данных
- Возврат геометрии текстов и символов
- Возврат альтернатив распознавания каждого символа
- Автоматическое определение типа документа
Какие документы
распознаются
Возможности
интеграции
DocEngine engine = DocEngine.Create(<PATH_TO_CONFIGURATION_FILE>, true);
DocSessionSettings settings = engine.CreateSessionSettings();
settings.SetCurrentMode("primary_accounting");
settings.AddEnabledDocumentTypes("*");
DocSession session = engine.SpawnSession(settings, <PERSONALIZED_SIGNATURE>);
DocProcessingSettings proc_settings = session.CreateProcessingSettings();
Image image = Image.FromFile(<PATH_TO_IMAGE>);
session.ProcessImage(image, proc_settings);
DocResult result = session.GetCurrentResult();
Document document = result.DocumentsBegin().GetDocument();
for (DocTextFieldsIterator iterator = doc.TextFieldsBegin(); !iterator.Equals(doc.TextFieldsEnd()); iterator.Advance()) {
String name = iterator.GetField().GetBaseFieldInfo().GetName();
String value = iterator.GetField().GetOcrString().GetFirstString().GetCStr();
}
std::unique_ptr<se::doc::DocEngine> engine(se::doc::DocEngine::Create(<PATH_TO_CONFIGURATION_FILE>, true));
std::unique_ptr<se::doc::DocSessionSettings> settings(engine->CreateSessionSettings());
settings->SetCurrentMode("primary_accounting");
settings->AddEnabledDocumentTypes("*");
std::unique_ptr<se::doc::DocSession> session(engine->SpawnSession(*settings, <PERSONALIZED_SIGNATURE>));
std::unique_ptr<se::doc::DocProcessingSettings> proc_settings(session->CreateProcessingSettings());
std::unique_ptr<se::common::Image> image(se::common::Image::FromFile(<PATH_TO_IMAGE>));
session->ProcessImage(*image, proc_settings.get());
const se::doc::DocResult& result = session->GetCurrentResult();
const se::doc::Document& doc = result.DocumentsBegin().GetDocument();
for (auto iterator = doc.TextFieldsBegin(); iterator != doc.TextFieldsEnd(); ++iterator) {
std::string name = iterator.GetFieldPtr()->GetBaseFieldInfo().GetName();
std::string value = iterator.GetFieldPtr()->GetOcrString().GetFirstString().GetCStr();
}
DocEngine engine = DocEngine.Create(<PATH_TO_CONFIGURATION_FILE>, true);
DocSessionSettings settings = engine.CreateSessionSettings();
settings.SetCurrentMode("primary_accounting");
settings.AddEnabledDocumentTypes("*");
DocSession session = engine.SpawnSession(session_settings, <PERSONALIZED_SIGNATURE>);
DocProcessingSettings proc_settings = session.CreateProcessingSettings();
Image image = Image.FromFile(<PATH_TO_IMAGE>);
session.ProcessImage(image, proc_settings);
DocResult result = session.GetCurrentResult();
doc_it = recog_result.DocumentsBegin()
Document doc = recog_result.DocumentsBegin().GetDocument();
for (DocTextFieldsIterator iterator = doc.TextFieldsBegin(); !iterator.Equals(doc.TextFieldsEnd()); iterator.Advance()) {
String name = iterator.GetField().GetBaseFieldInfo().GetName();
String value = iterator.GetField().GetOcrString().GetFirstString().GetCStr());
}
engine = pydocengine.DocEngine.Create(<PATH_TO_CONFIGURATION_FILE>)
settings = engine.CreateSessionSettings()
settings.SetCurrentMode("primary_accounting")
settings.AddEnabledDocumentTypes("*")
session = engine.SpawnSession(settings, <PERSONALIZED_SIGNATURE>)
proc_settings = session.CreateProcessingSettings()
image = pydocengine.Image.FromFile(<PATH_TO_IMAGE>)
session.ProcessImage(image, proc_settings)
result = session.GetCurrentResult()
doc_it = recog_result.DocumentsBegin()
doc = recog_result.DocumentsBegin().GetDocument()
iterator = doc.TextFieldsBegin()
while(iterator != doc.TextFieldsEnd()):
name = iterator.GetField().GetBaseFieldInfo().GetName()
value = iterator.GetField().GetOcrString().GetFirstString().GetCStr()
iterator.Advance()
Уверенность распознавания, координаты объектов, вырезание полей и документов
Возврат зоны принятия решения для проверок подлинности

Попробуйте качество наших технологий
- Скачайте мобильное демо-приложение, в котором все возможности собраны воедино
- Можно на время отключить интернет, чтобы убедиться, что изображения и ваши данные не передаются
- Извлекайте данные паспортов, удостоверений личности и других документов. Пробуйте распознавать оригиналы и копии при различных условиях съемки


