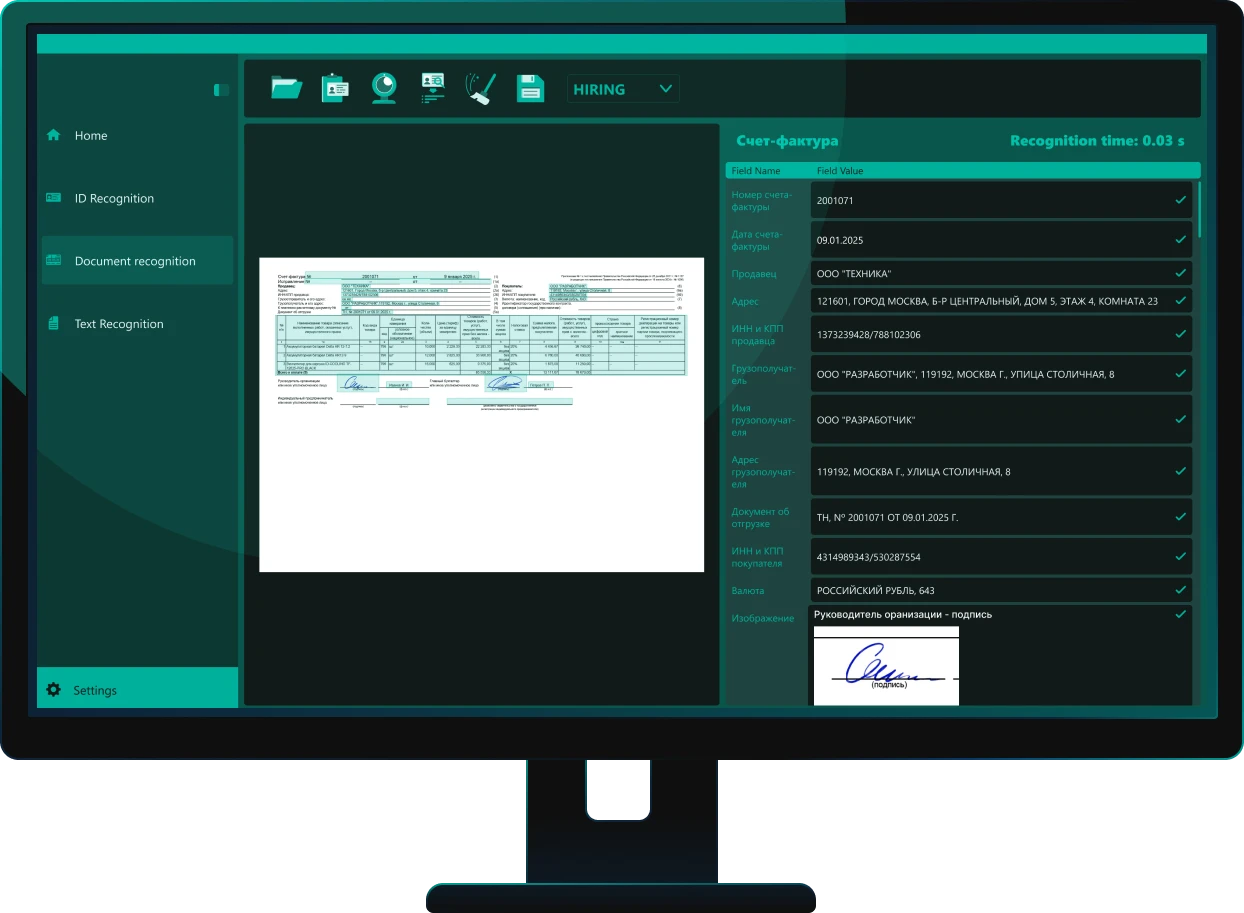


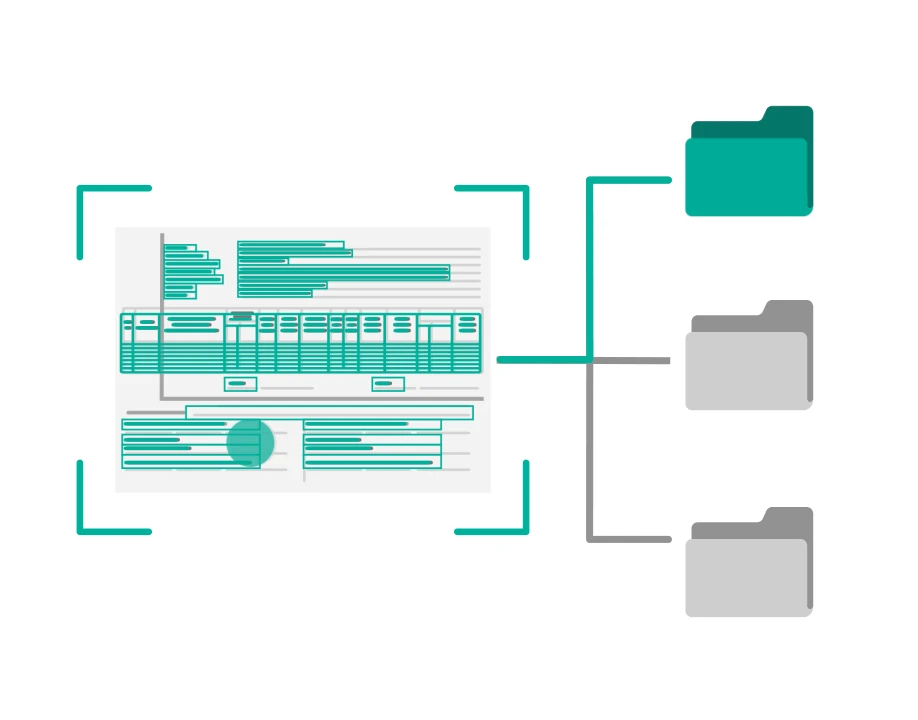



Искусственный интеллект автоматически определяет тип документа, извлекает ключевые реквизиты и подготавливает данные для регистрации в СЭД и ECM-системах без ручного ввода. Решение распознает договоры, счета, акты, письма, заявления, кадровые и бухгалтерские документы, формируя структурированный результат. Это позволяет сократить время регистрации документов, снизить количество ошибок ручного ввода и ускорить обработку входящего потока документов.
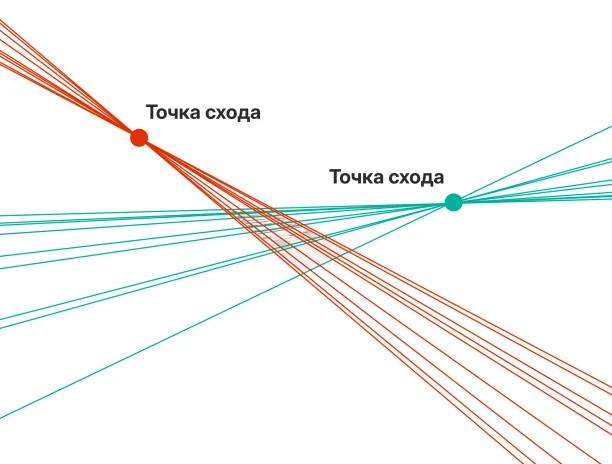
Технология Smart Engines применяет уникальные Хаф-сети для интеллектуального выравнивания, разглаживания и нормализации изображений документов перед распознаванием. Алгоритмы ИИ автоматически устраняют перекосы, деформации страниц, изгибы бумаги и геометрические искажения, возникающие при сканировании и мобильной съемке. Это обеспечивает высокую точность извлечения данных даже при работе с документами, снятыми в «неидеальных» условиях.
Система обеспечивает полностью автоматический ввод документов на сканах и фотографиях в СЭД и ECM-платформы без необходимости ручной сортировки и перепечатки данных. Искусственный интеллект извлекает реквизиты документа и предоставляет структурированный результат для интеграции в корпоративные системы. Решение позволяет значительно снизить нагрузку на сотрудников, ускорить обработку документов и повысить качество данных в цифровом архиве компании.
Система Smart Engines использует современные алгоритмы бинаризации изображений для повышения качества распознавания корпоративных документов любой сложности. Искусственный интеллект надежно распознает документы, даже если на изображении присутствуют шумы, артефакты сканирования и дефекты печати. Это обеспечивает высокоточное распознавание данных даже при работе с частично поврежденными документами.
Технология Smart Engines автоматизирует обработку входящей корреспонденции для канцелярий, сервисных центров и других отделов. Искусственный интеллект распознает письма, обращения, заявления и сопроводительные документы, автоматически извлекая данные отправителя, дату, номер и другие реквизиты для регистрации в СЭД. Это позволяет сократить время обработки входящих документов и ускорить маршрутизацию документов между подразделениями.
Архитектура Smart Engines обеспечивает высокоскоростную обработку больших массивов документов для массовой оцифровки архивов и потокового ввода данных в СЭД/ECM. Решение эффективно масштабируется под любые корпоративные нагрузки и позволяет обрабатывать сотни тысяч страниц без использования GPU и усложнения инфраструктуры. Высокая производительность системы помогает ускорить цифровую трансформацию документооборота и снизить затраты на обработку архивов.
Система поддерживает все основные форматы файлов и изображений: JPEG (JPG), PNG, TIFF, многостраничные PDF, а также сканы и фотографии документов. Искусственный интеллект автоматически извлекает текст и реквизиты независимо от качества входящего изображения. Это позволяет применять решение для потоковой оцифровки архивов, ввода данных из документов с помощью мобильных устройств, а также в других корпоративных сценариях.
Технология Smart Engines подходит для массовой оцифровки бумажных архивов предприятий с возможностью автоматического экспорта в PDF с текстовым слоем. Система распознает содержимое архивных документов, делая их доступными для полнотекстового поиска, индексации и быстрого доступа из ECM-систем. Это позволяет существенно сократить время работы с архивами, ускорить поиск информации и быстро переводить бумажные фонды в цифровой формат без ручной обработки документов.
Система Smart Engines работает полностью локально в инфраструктуре организации без передачи документов и данных во внешние облачные сервисы. Обработка выполняется внутри защищенного контура заказчика, что обеспечивает высокий уровень конфиденциальности и соответствие требованиям информационной безопасности. Решение подходит для банков, государственных организаций, промышленности и компаний, работающих с коммерческой тайной и персональными данными.
Как работает распознавание для СЭД и ECM
Программное обеспечение на базе искусственного интеллекта для распознавания в СЭД и ECM позволяет автоматически вводить документы в цифровой контур организации без ручной обработки. Решение классифицирует бухгалтерские и корпоративные документы, извлекает реквизиты, подготавливает материалы к регистрации в системе, распознает входящую корреспонденцию с экспортом в PDF с текстовым слоем. Система работает со сканами, фотографиями и многостраничными PDF, включая изображения низкого качества. Используются современные методы бинаризации, выравнивания и нормализации документов, а также компактные 4.6-битные нейросети для быстрого распознавания на CPU без GPU. ПО работает полностью в контуре заказчика, обрабатывая до 1800 страниц в минуту на сервере.
Возможности распознавания
- Автоматическая классификация бухгалтерских и корпоративных документов перед загрузкой в СЭД и ECM
- Извлечение реквизитов для заполнения регистрационных карточек
- Подготовка документов к регистрации в системе без ручного ввода
- Обработка сканов, фотографий и многостраничных PDF-документов
- Потоковое распознавание больших массивов документов и архивов
- Распознавание сканов и фотографий низкого качества
- Поиск, выравнивание и нормализация документа на фотографии
- Распознавание документа А4 на смартфоне за 2-3 секунды
- GreenOCR® — экологичный искусственный интеллект распознавания текста
- Уникальные 4.6 битные нейросетевые модели для скоростного распознавания на CPU
- Распознавание силами CPU, не требует ресурсов GPU и NPU
- Высокоточное распознавание текста на фото и скане
- Полнотекстовое распознавание бумажных архивов с экспортом в PDF с текстовым слоем
- State-of-the-art бинаризация изображений корпоративных документов
- Автоматическое определение типа документа
- Выравнивание, разглаживание и нормализация изображений документов
- Поиск границ документа на фото и автоматическая коррекция перспективы
- Высокоточное распознавание печатного текста на документах различного качества
- Распознавание таблиц, штампов, печатей, пометок и служебных отметок
- Распознавание полностью рукописных документов, смешанных текстов и пометок
- Работа полностью в контуре заказчика без передачи данных во внешние сервисы
- Высокая производительность обработки архивных и текущих потоков документов на CPU
Какие документы
распознаются
Возможности
интеграции
DocEngine engine = DocEngine.Create(<PATH_TO_CONFIGURATION_FILE>, true);
DocSessionSettings settings = engine.CreateSessionSettings();
settings.SetCurrentMode("primary_accounting");
settings.AddEnabledDocumentTypes("*");
DocSession session = engine.SpawnSession(settings, <PERSONALIZED_SIGNATURE>);
DocProcessingSettings proc_settings = session.CreateProcessingSettings();
Image image = Image.FromFile(<PATH_TO_IMAGE>);
session.ProcessImage(image, proc_settings);
DocResult result = session.GetCurrentResult();
Document document = result.DocumentsBegin().GetDocument();
for (DocTextFieldsIterator iterator = doc.TextFieldsBegin(); !iterator.Equals(doc.TextFieldsEnd()); iterator.Advance()) {
String name = iterator.GetField().GetBaseFieldInfo().GetName();
String value = iterator.GetField().GetOcrString().GetFirstString().GetCStr();
}
std::unique_ptr<se::doc::DocEngine> engine(se::doc::DocEngine::Create(<PATH_TO_CONFIGURATION_FILE>, true));
std::unique_ptr<se::doc::DocSessionSettings> settings(engine->CreateSessionSettings());
settings->SetCurrentMode("primary_accounting");
settings->AddEnabledDocumentTypes("*");
std::unique_ptr<se::doc::DocSession> session(engine->SpawnSession(*settings, <PERSONALIZED_SIGNATURE>));
std::unique_ptr<se::doc::DocProcessingSettings> proc_settings(session->CreateProcessingSettings());
std::unique_ptr<se::common::Image> image(se::common::Image::FromFile(<PATH_TO_IMAGE>));
session->ProcessImage(*image, proc_settings.get());
const se::doc::DocResult& result = session->GetCurrentResult();
const se::doc::Document& doc = result.DocumentsBegin().GetDocument();
for (auto iterator = doc.TextFieldsBegin(); iterator != doc.TextFieldsEnd(); ++iterator) {
std::string name = iterator.GetFieldPtr()->GetBaseFieldInfo().GetName();
std::string value = iterator.GetFieldPtr()->GetOcrString().GetFirstString().GetCStr();
}
DocEngine engine = DocEngine.Create(<PATH_TO_CONFIGURATION_FILE>, true);
DocSessionSettings settings = engine.CreateSessionSettings();
settings.SetCurrentMode("primary_accounting");
settings.AddEnabledDocumentTypes("*");
DocSession session = engine.SpawnSession(session_settings, <PERSONALIZED_SIGNATURE>);
DocProcessingSettings proc_settings = session.CreateProcessingSettings();
Image image = Image.FromFile(<PATH_TO_IMAGE>);
session.ProcessImage(image, proc_settings);
DocResult result = session.GetCurrentResult();
doc_it = recog_result.DocumentsBegin()
Document doc = recog_result.DocumentsBegin().GetDocument();
for (DocTextFieldsIterator iterator = doc.TextFieldsBegin(); !iterator.Equals(doc.TextFieldsEnd()); iterator.Advance()) {
String name = iterator.GetField().GetBaseFieldInfo().GetName();
String value = iterator.GetField().GetOcrString().GetFirstString().GetCStr());
}
engine = pydocengine.DocEngine.Create(<PATH_TO_CONFIGURATION_FILE>)
settings = engine.CreateSessionSettings()
settings.SetCurrentMode("primary_accounting")
settings.AddEnabledDocumentTypes("*")
session = engine.SpawnSession(settings, <PERSONALIZED_SIGNATURE>)
proc_settings = session.CreateProcessingSettings()
image = pydocengine.Image.FromFile(<PATH_TO_IMAGE>)
session.ProcessImage(image, proc_settings)
result = session.GetCurrentResult()
doc_it = recog_result.DocumentsBegin()
doc = recog_result.DocumentsBegin().GetDocument()
iterator = doc.TextFieldsBegin()
while(iterator != doc.TextFieldsEnd()):
name = iterator.GetField().GetBaseFieldInfo().GetName()
value = iterator.GetField().GetOcrString().GetFirstString().GetCStr()
iterator.Advance()
Уверенность распознавания, координаты объектов, вырезание полей и документов
Возврат зоны принятия решения для проверок подлинности

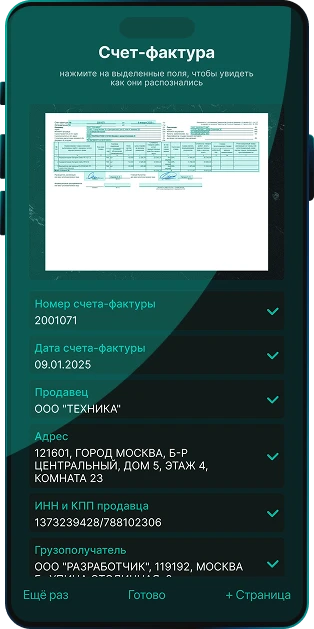
Попробуйте качество наших технологий
- Скачайте мобильное демо-приложение, в котором все возможности собраны воедино
- Можно на время отключить интернет, чтобы убедиться, что изображения и ваши данные не передаются
- Извлекайте данные паспортов, удостоверений личности и других документов. Пробуйте распознавать оригиналы и копии при различных условиях съемки.


